
Пошаговое руководство о том, как можно предсказать движение цен на акции, построив модель CNN, которая обучается на изображениях ценовых графиков.
Отказ от ответственности: Информация, представленная в этом блоге, предназначена исключительно для образовательных и информационных целей. Она не должна восприниматься как инвестиционная или финансовая консультация, а также как рекомендация покупать или продавать какие-либо ценные бумаги. Все высказанные мнения являются моими собственными и основаны на личном анализе. Пожалуйста, проводите собственное исследование или консультируйтесь с лицензированным финансовым консультантом перед принятием любых инвестиционных решений. Прошлая производительность не является показателем будущих результатов, и все инвестиции связаны с риском, включая потерю основной суммы.
Данные предоставлены Financial Modeling Prep.
Введение
В своем бесконечном стремлении овладеть искусством дневной и свинг-торговли я провел много часов, пытаясь найти лучшие техники для максимизации шансов на успех. В конечном итоге, все, чего я добился до сих пор, – это часы, проведенные за изучением графиков, и приблизительно нулевые результаты. Тем временем я продолжал держать акции на долгий срок и применять стратегию усреднения по затратам, что, в свою очередь, гораздо менее трудоемко, проверено временем и значительно проще с точки зрения психологии трейдинга.
Это, однако, не означает, что моё стремление к успешной стратегии дневной/свинг-торговли окончено — совсем наоборот. Поэтому я начал думать о различных способах, как я мог бы применить свои навыки в области Data Science к торговле, желательно необычным образом. Однажды, просматривая график ETF SPY, я пытался найти ключевые уровни цен, лучшие временные рамки для анализа и применяя бесчисленные комбинации линий скользящих средних. Затем меня осенило: я смотрю на множество различных изображений и классифицирую их одним из двух способов: бычий или медвежий. Это и есть суть задачи классификации изображений.
В этой статье я проведу читателя через процесс создания модели классификации изображений, а именно сверточной нейронной сети (CNN) на Python с использованием данных от Financial Modeling Prep (FMP), которая предсказывает, будет ли уровень ETF SPY выше через неделю по сравнению с сегодняшним закрытием. Обратите внимание, что будет полезно для читателя иметь хотя бы основное понимание нейронных сетей. В противном случае я постараюсь объяснить эти сложные концепции!
Предобработка изображений
Вы когда-нибудь задумывались о том, как изображение может быть использовано для построения модели классификации? Если у вас есть хоть немного опыта в машинном обучении или Data Science, вы должны знать, что модель классификации — это, по сути, набор правил, которые компьютер может использовать для принятия какого-либо наблюдения, в нашем случае – изображения, и предсказания, к какому классу оно принадлежит. Например, если у вас есть данные о личных расходах и банковских операциях, вы могли бы обучить компьютер предсказывать, будет ли клиент дефолтить по кредиту.
Отлично в упомянутом наборе данных то, что он требует некоторого масштабирования и нормализации признаков для эффективного построения модели. Однако с изображениями предобработка гораздо более сложная. Поскольку мы имеем дело с математической моделью, нам нужны реальные числа для её обучения. Как мы вообще можем начать встраивать изображение в модель, которая требует числовые значения? Давайте рассмотрим практический пример.
Предположим, вы создаете модель классификации изображений, которая предсказывает рукописные цифры. Давайте рассмотрим цифру “0”.

Обратите внимание, что это будет одно из множества изображений в нашем наборе данных. Как нам заполнить разрыв между изображением и его корректным форматированием для обучения модели? Мы разбиваем его на сетку, обычно по пикселям. После этого у нас остаётся сечение изображения. Наконец, мы преобразуем каждую ячейку в сетке в число. Это не будет случайное число; оно будет основано на некоторой цветовой шкале. Например, на изображении выше видны только два цвета: серый и черный. Поэтому для каждой ячейки в нашей сетке у нас будет диапазон чисел от 0 до 1. 0 для серой ячейки и 1 для черной. Если есть смесь, когда ячейка наполовину серая и наполовину черная, значение для этой ячейки будет 0.5. У Python есть много инструментов, которые позволяют нам выполнить эту задачу в больших объемах. Давайте посмотрим, как может выглядеть наша обновлённая сетка для числа “0”.

Это не совсем точно отражает, как изображение будет предварительно обработано в Python (я делал это вручную); однако посмотри, сможешь ли ты это понять. «1» в сетке представляют части изображения «0», где черный цвет полностью охвачен. На внешних частях видно, что в основном они состоят из числа 0,5. Здесь мы можем увидеть кривые изображения «0», которые не полностью занимают всю ячейку. Обратите внимание, что это можно применить даже к изображениям с цветами. Однако это выходит за рамки того, на чем я хочу сосредоточиться в этой истории.
Теперь у нас есть базовое понимание того, как изображение может быть преобразовано в числовое представление, что открывает бесконечные возможности с точки зрения моделирования. Теперь давайте погрузимся в то, как это будет работать с фреймворком глубокого обучения, который мы будем использовать для построения нашей модели классификации изображений — сверточной нейронной сетью.
Что такое сверточная нейронная сеть (CNN)?
CNN — это фреймворк глубокого обучения, который в основном используется для задач классификации изображений и обнаружения объектов. Это критически важный компонент технологии автономных автомобилей.
С моей точки зрения, магия CNN заключается в том, как она может преобразовать.Grid-представление изображения в небольшое математическое представление особенностей изображения. Например, если вы обучаете CNN распознавать изображения животных, вы можете узнать, есть ли у животного на изображении хвост, какой тип носа, зубов и так далее. Как она это делает?
Я нашел отличное представление ниже, которое иллюстрирует, как CNN обучается на данных изображений:
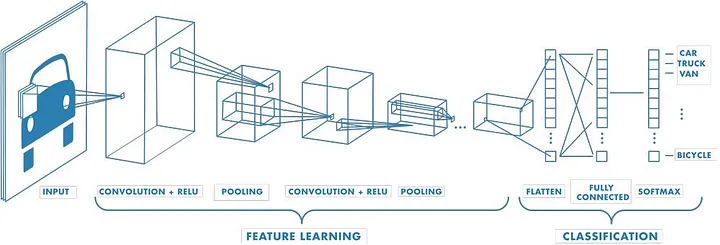
Вы начинаете с представления вашего изображения в виде сетки. Отсюда сверточная нейронная сеть (CNN) будет работать на уменьшение размерности, фильтруя поперечный срез в более мелкую сетку. Это достигается с помощью более мелкой матрицы, обычно со случайными числами, которая сканирует изображение, вычисляя скалярное произведение между мелкой матрицей и участком изображения, а затем, используя сумму этого скалярного произведения, создается новое представление изображения с меньшей размерностью. Обратите внимание, что эта мелкая матрица обычно называется фильтром или ядром. Посмотрите на изображение ниже и не стесняйтесь посетить веб-сайт, откуда я его взял, чтобы увидеть отличную демонстрацию того, как этот процесс работает. Мы математически уменьшили размерность изображения; однако мы все еще можем визуализировать извлеченные особенности. Например, фильтр ниже предназначен для обнаружения горизонтальных краев в изображении.

Этот шаг можно повторять несколько раз, и в конечном итоге мы хотим преобразовать финальное объединенное изображение в одноразмерную матрицу, где мы сможем применить некоторую активационную функцию, которая предскажет, что изображение изображает. С этого момента процесс обратного распространения ошибки улучшает точность сети. Обратное распространение тоже выходит за рамки того, что я хочу рассмотреть в этой статье, по крайней мере, в глубину. Просто знайте, что это рамочная конструкция, используемая в нейронных сетях, которая позволяет сети учиться на своих ошибках и улучшаться со временем. Она выполняет эту задачу, неоднократно анализируя метрики ошибок и используя их для корректировки весов модели. Я люблю думать об этом как о идеальных отношениях между тренером и игроком. Тренер постоянно дает обратную связь о том, над чем игроку нужно работать, и, в свою очередь, игрок постепенно начинает показывать лучшие результаты.
Импорт наших данных и библиотек
Мы рассмотрели необходимую базовую информацию, так что давайте построим нашу структуру в Python. Начнем с импорта всех необходимых библиотек и данных из Financial Modeling Prep (FMP). Напоминаю, что мы будем строить CNN, который предскажет, будет ли цена ETF SPY выше через неделю по сравнению с текущей ценой.
Что касается наших данных, я буду использовать собственный класс, который я создал на Python и который называется SP500data. Он предназначен для импорта данных о компаниях, входящих в S&P 500; однако у него есть встроенная функция, которая может импортировать данные для любых акций. Ознакомьтесь с моей статьей об этом ниже! В этой статье я использую упрощенную версию, которая приведена ниже.
После импорта наших данных мы добавим новый пользовательский столбец под названием Direction, который будет “1”, если цена через n дней будет выше текущей цены; в противном случае он будет “0”. В нашем случае n будет равно 5. Тем не менее, я сделал эту логику динамичной, чтобы конечный пользователь мог использовать любой период прогнозирования.
## Libraries
import requests
import pandas as pd
import numpy as np
from tqdm import tqdm
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
import cv2
import matplotlib.pyplot as plt
from datetime import datetime
import os
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.preprocessing import image_dataset_from_directory
from tensorflow.keras.callbacks import EarlyStopping
from pathlib import Path
from datetime import datetime## Simplified version of the SP500data class
class SP500data:
def __init__(self, api_key):
self.api_key = api_key
## Symbols and Profiles
self.symbol_list = []
## Price
self.price_data = {}
def get_symbols(self):
url = f'https://financialmodelingprep.com/api/v3/sp500_constituent?apikey={self.api_key}'
stocks = requests.get(url).json()
self.symbol_list = [stock['symbol'] for stock in stocks]
def fetch_price(self, symbol):
url = f'https://financialmodelingprep.com/api/v3/historical-price-full/{symbol}?apikey={self.api_key}'
response = requests.get(url).json()
prices_df = pd.DataFrame(response['historical'])
prices_df = prices_df.sort_values(by='date').reset_index(drop=True)
return prices_df
def fetch_price_data(self):
with ThreadPoolExecutor(max_workers=10) as executor:
future_to_symbol = {executor.submit(self.fetch_price, symbol): symbol for symbol in self.symbol_list}
for future in tqdm(as_completed(future_to_symbol), total=len(self.symbol_list)):
try:
symbol = future_to_symbol[future]
prices_df = future.result()
self.price_data[symbol] = prices_df
except Exception as exc:
print(f'Exception for {symbol}: {exc}')api_key = 'your_fmp_api_key_here'
data_obj = SP500data(api_key = api_key)
symbol = 'spy'
df = data_obj.fetch_price(symbol=symbol)
df = df[['date','close']]
n = 5
df[f'{n}_days_price'] = df.close.shift(-n)
df['Direction'] = np.where(df[f'{n}_days_price'] > df.close, 1, 0)
df = df.dropna()Дополнительные функции и получение изображений
Теперь у нас есть датафрейм ETF SPY с датами, ценами закрытия и направлением цен через пять дней. Наши данные далеки от того, чтобы быть готовыми для обработки сверточной нейронной сетью. Сначала нам нужно получить изображения графиков для каждого торгового дня. Мы создадим эти изображения с помощью matplotlib и сохраним их в нашей рабочей директории. После того как мы их создадим, мы импортируем их с использованием библиотеки cv2, которая отлично подходит для работы с изображениями, предназначенными для глубокого обучения. Чтобы выполнить эти две задачи, я создал две функции: save_image и load_data. Вот краткий предварительный просмотр того, как выглядит одно из изображений:
Обратите внимание на последнюю строку кода в этом разделе, где я отображаю форму одного из изображений. Она составляет (128,128,3). Каждое изображение имеет размер 128 на 128 пикселей и три цветовых канала (красный, зеленый и синий). Это добавляет дополнительную сложность к нашим изображениям, хотя мы могли бы использовать только один цветовой канал, поскольку наши изображения по сути имеют белый фон и одну цветную линию. Почему я этого не сделал? Я планирую использовать этот код в будущих проектах и хочу, чтобы он был достаточно динамичным для обработки различных цветов. Так что, прочитав эту историю, оставайтесь с нами для будущих итераций!
def save_image(df, symbol, date, direction):
# Plot
plt.figure(figsize=(1, 1))
plt.plot(df['date'], df['close'])
# Hide the x-axis and y-axis
plt.gca().axes.get_xaxis().set_visible(False)
plt.gca().axes.get_yaxis().set_visible(False)
# Hide the frame
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
filename = f'{symbol}_{direction}_{date}.png'
# Save the plot as an image file
plt.savefig(filename, bbox_inches='tight')def load_data():
images = []
labels = []
for filename in os.listdir('.'): # No need to specify image_dir, just use current directory '.'
if filename.endswith(".png"):
# Extract label from the filename (second part)
label = int(filename.split('_')[1])
# Load the image using OpenCV (cv2)
image = cv2.imread(filename, cv2.IMREAD_COLOR) # Read in color
image = cv2.resize(image, (128, 128)) # Resize images to 128x128 pixels (adjustable)
images.append(image)
labels.append(label)
# Convert lists to numpy arrays
images = np.array(images)
labels = np.array(labels)
return images, labelslookback_period = 60
for i in tqdm(range(len(df.index)-(lookback_period+1))):
start = i
end = i+lookback_period
temp_df = df.loc[start:end]
date = temp_df.tail(1)['date'].values[0]
direction = temp_df.tail(1)['Direction'].values[0]
save_image(df = temp_df, symbol = symbol,date = date, direction = direction)# Load the data from the current working directory
images, labels = load_data()
# Normalize pixel values to be between 0 and 1
images = images / 255.0
images[0].shape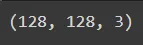
Обучение модели

Мы разделим наши данные изображений и меток на обучающую и тестовую выборки, чтобы начать фазу обучения. Аргумент test_size позволяет легко изменять процент ваших данных, используемых для обучения и тестирования.
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(images, labels, test_size=0.2, random_state=42)Ниже приведено всего несколько строк кода; однако они представляют собой сложную сверточную нейронную сеть (честно говоря, любая CNN сложна). Давайте разберем это. Я сделаю ссылки на некоторые концепции, обсуждавшиеся в разделе «Что такое сверточная нейронная сеть».
Ниже вы можете увидеть три комбинации tf.keras.layers.Conv2D и tf.keras.layers.MaxPooling. Оба этих метода представляют собой слои в нашей нейронной сети. Класс Conv2D представляет собой сверточный слой. Первый аргумент обозначает количество фильтров, применяемых к изображению. Далее идут размеры фильтров. Наш первый сверточный слой использует 32 фильтра размером 3×3, создавая 32 новых изображения. Чтобы снизить размерность и избежать переобучения, каждый сверточный слой в нашей сети также уменьшает размерность с помощью техники, известной как максимальное объединение. Класс MaxPooling способен сделать это за нас. Каждый слой максимального объединения использует размер пула 2×2 в нашей сети. Это означает, что он просматривает все изображение с помощью фильтра 2×2 и извлекает максимальное значение пикселя в каждом шаге. Затем мы повторяем этот процесс снова и снова. Обратите внимание, что в последующих сверточных слоях больше фильтров. Это связано с тем, что нам нужно использовать больше фильтров, чтобы захватить более сложную информацию на изображении. Нет правильного ответа на вопрос, сколько сверточных слоев, количество фильтров, размер объединения и т. д. использовать в сверточной нейронной сети; вместо этого вы получите интуицию о том, что работает лучше, по мере построения большего количества моделей. К счастью, существует много заранее подготовленных моделей. Вы также заметите аргумент activation = ‘relu’. Relu — это сокращение от Rectified Linear Unit. Он преобразует отрицательные числа в 0 и сохраняет положительные числа без изменений. В контексте сверточной нейронной сети это помогает модели учить нелинейные паттерны и улучшать вычислительную эффективность. Наконец, мы реализуем шаг Flatten, который преобразует наш последний слой в одно измерение, что можно использовать для предсказания нашего финального вывода: “1”, если модель предсказывает, что рынок вырастет; в противном случае это “0”.
После построения модели мы можем использовать метод summary, чтобы создать легко читаемую таблицу функций нашей модели с точки зрения слоев, размеров и количества параметров.
Наконец, давайте посмотрим, насколько точна эта модель. 62% точности — это вовсе не плохо! Это указывает на то, что наша модель, как минимум, имеет доказательства того, что она может лучше предсказывать, пойдет ли рынок вверх или вниз, чем бросание монеты.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(128, 128, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid') # Binary classification
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()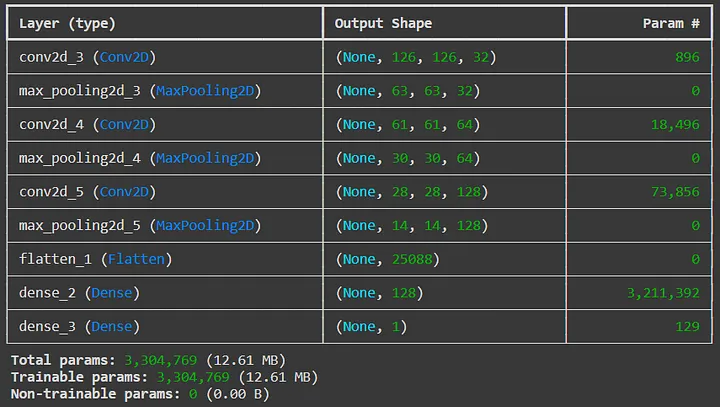
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))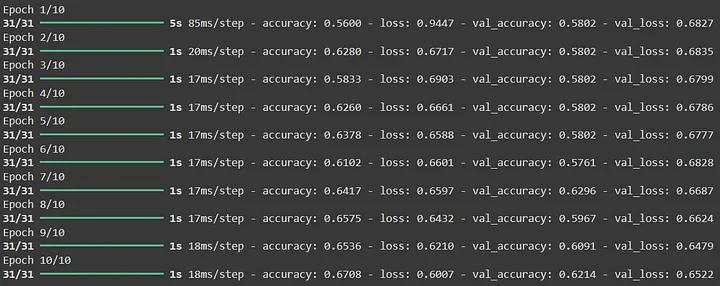
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=2)
print(f'Test accuracy: {test_acc}')
Заключение
Надеюсь, вам понравился этот проект! Я обожаю находить пересечения между финансами и огромным миром машинного обучения (смогу ли я теперь сказать ИИ?). Если вы кодировали вместе со мной, попробуйте разные комбинации временных окон, логику для целевой переменной, количество сверточных слоев, фильтры, размеры фильтров и многое другое! С такими моделями возможности безграничны. Если вам интересна эта тема, я настоятельно рекомендую углубить изучение нейронных сетей и глубокого обучения. Ожидайте еще больше статей на эту тему!
Литература
- MathWorks. (n.d.). What is a Convolutional Neural Network? MathWorks. https://www.mathworks.com/discovery/convolutional-neural-network.html
- Setosa. (n.d.). Image Kernels. Setosa. https://setosa.io/ev/image-kernels/



Обсуждение закрыто.