
Индустрия искусственного интеллекта — это скорее религия, чем наука
Чрезвычайно снисходительный, невыносимо высокомерный и принимающий решения на основе веры. Вот что собой представляет индустрия ИИ сегодня.
Участвующие в ней, пьянствующие от собственных оценок, иллюзий и предвзятостей, думают, что они обладают самой важной технологией, когда-либо созданной, несмотря на ясные сигналы общества о том, что это не так (по крайней мере сейчас). Непоколебимо, они отчаянно пытаются навязать нам продукты, которые никто не просил, что, как и следовало ожидать, приводит к провалу за провалом.
Тем не менее, их настойчивость удивительна, и они высокомерно настаивают на наборе догм, которые стимулируют крупнейшие инвестиции в истории капитализма, основанные лишь на предвзятых прогнозах их собственных убеждений.
Позвольте мне провести вас по пути/проверке реальности индустрии ИИ, которую участники не хотят, чтобы вы читали.
Урок за 600 миллиардов долларов
Темпы инвестиций в индустрию Искусственного Интеллекта не знают границ, и за это можно винить две вещи: горький урок и большой страх.
Вопрос на 600 миллиардов долларов
600 миллиардов долларов – это та бездна инвестиций, в которую ввалились устоявшиеся игроки, согласно данным Sequoia Capital (веселая деталь: сама Sequoia Capital является одним из таких игроков).
Тем не менее, четыре гипермасштабируемые компании (Amazon, Meta, Microsoft и Google) имеют прогнозируемые годовые капитальные затраты (долгосрочные инвестиции) в размере 210 миллиардов долларов; всего четыре компании тратят на Генеративный ИИ столько же, сколько составляет ВВП Греции.
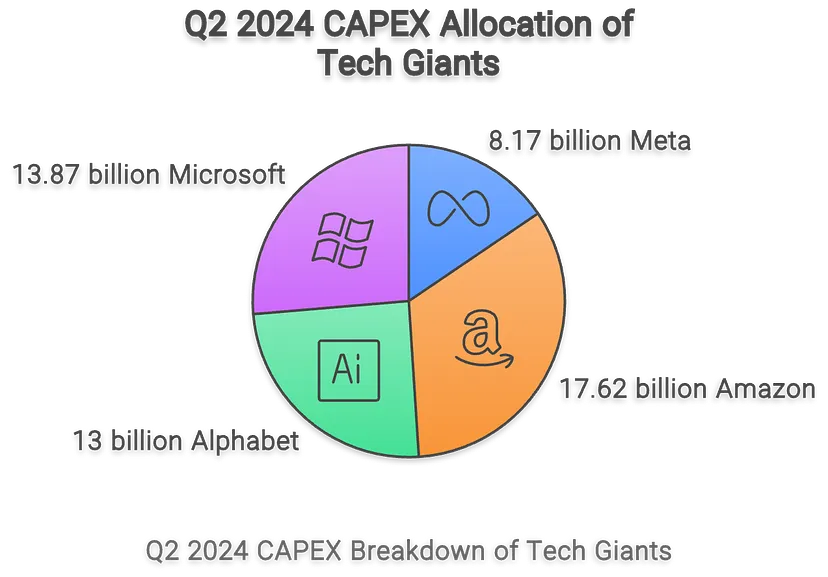
А какова доходность таких инвестиций?
Давайте рассмотрим факты. Общая выручка всей отрасли (без учета NVIDIA) составляет от 30 до 50 миллиардов долларов в этом году, при этом вероятность того, что цифра будет ближе к нижней границе, почти гарантирована.
В частности:
- Согласно исследованию Скотта Гэллоуэя, объединённый прогнозируемый оборот Amazon, Google и Microsoft составляет всего 20 миллиардов долларов. Точные цифры нам неизвестны, но ни одна из компаний не раскрывает значительных данных о своих доходах от Генеративного ИИ в своих отчетах, несмотря на очевидный интерес. Дела говорят громче слов.
- OpenAI процветает, с почти 4 миллиарда долларов ежегодной повторяющейся выручки. Однако в этом году они близки к потере 5 миллиардов долларов, оставаясь крайне убыточными и вынужденными проводить новый инвестиционный раунд на 6 миллиардов долларов в “аналогах наличных” (наличные или кредиты на вычисления) плюс 5 миллиардов долларов в долг.
- С другой стороны, Google Gemini и Anthropic испытывают трудности с тем, чтобы оказывать заметное влияние на прямых потребителей. Согласно The Information, их совокупная доля рынка составляет 5%, в то время как у OpenAI — более 80% от общей доли. Это не только подрывает их усилия, но и свидетельствует о том, как мала ниша Генеративного ИИ для прямых потребителей.
- С точки зрения открытого кода, Meta практически захватила весь рынок, оставив лишь крохи для поставщиков корпоративных больших языковых моделей (LLM), которые, несмотря на наличие значительного свободного капитала и приемлемых оценок, сталкиваются с очень сложной задачей конкурировать с экономией от масштаба, которой обладают гиперскейлеры (особенно когда речь идет о сроках службы GPU и их показателях отказов).
- Что касается продуктов, кроме ChatGPT, остальная часть отрасли сталкивается с одной неудачей за другой. Недавняя статья The Verge о «умных» очках Meta является ясным примером всего, что не так в этой индустрии; успех Meta не основан на наличии увлекательного продукта, от которого невозможно оторваться, причина, по которой носимые устройства Meta более успешны, а такие, как AI Pin от Human или Rabbit’s R1, — нет, заключается в том, что, в отличие от остальных, это… в какой-то степени работает? Да, планка успеха так низка.
В конце концов, рынок ИИ — это ни что иное, как инцестуальные отношения между компанией, контролирующей более 50% доходов и всей прибылью отрасли, NVIDIA, и небольшим набором богатых корпораций, которые покупают каждый продукт, который может произвести NVIDIA.
Другими словами, дело не в том, что деньги текут рекой, поскольку люди не могут насытиться продуктами ИИ; большая часть прибыли поступает изнутри. Короче говоря, выгоды от этой индустрии еще предстоит осознать.
И, несмотря на все это, расходы только нарастают. Но почему?
Религия вычислений
Вы не найдете единого эссе, которое цитировалось бы чаще в Кремниевой долине, чем «Горький урок» Рича Саттона. Это короткое чтение, но его суть довольно проста: ничего не имеет значения, кроме вычислений, и каждое прорывное открытие данных и алгоритмов ведет к прогрессу ИИ, поскольку оно позволяет выделять больше вычислительных ресурсов в масштабах.
Простыми словами, ответ на текущие ограничения ИИ заключается в увеличении уровня инвестиций в чипы и энергоресурсы. Как уже упоминалось, эта точка зрения повсеместна в отрасли, но немногие эссе представляют ее лучше, чем недавняя публикация Сэма Альтмана «Эпоха интеллекта».
В этой статье, которая, как и ожидалось, стала вирусной, учитывая, что он является одной из самых (если не самой) влиятельных фигур в отрасли, Сэм делится удивительно позитивным взглядом на будущее ИИ, вдали от — если быть откровенным, невыносимого — негативного взгляда на то, что ИИ очень опасен. Тем не менее, основная тематика блога, которая на первый взгляд не очевидна, — это необходимость в большем количестве энергии и чипов.
Короче говоря, это крик о помощи для разблокировки большего вычислительного потенциала, замаскированный под красивую аллегорию о будущем мира благодаря ИИ, что ведет нас к неопровержимому будущему ускоренного расходования средств на ИИ, чтобы сделать уже огромную инвестиционную дыру гораздо больше.
Все это кричит одно слово: высокомерие.
Но насколько много значит слово «больше» в предыдущем абзаце? Ну, аномально много.
Мы знаем лучше.
Тратный бум Кремниевой долины, питаемый верой в то, что мы уже все решили и нам нужно больше тратить на вычисления, исключительно высокомерен по двум причинам: технологическим и энергетическим ограничениям.
Не то чтобы это было идеально.
Я просто не понимаю этой приверженности эгоистичному убеждению, что нам не нужны дополнительные алгоритмические прорывы в ИИ.
Хотя OpenAI уже якобы нанимает команду для проведения исследований с многими агентами и покорения уровня AGI 3, предполагая, что они уже добились успеха на уровне 2, модели o1 не могут последовательно выполнять математические вычисления (тест рассматривает устойчивость, то есть получение ответа последовательно правильно), и они все еще очень-очень посредственные планировщики (ключевой шаг для рассуждений), согласно недавно опубликованной статье.
К слову, исследователи, стоящие за этой статьей, согласны со мной в том, что o1, скорее всего, является комбинацией LLM и алгоритма RL в стиле AlphaGo, возможно, более похожим на AlphaZero, чтобы избежать необходимости активно моделировать развертывания.
Учитывая все это, мне жаль, но утверждение, что модели o1 решили задачу «рассуждающий ИИ», просто возмутительно. Существуют бесчисленное множество примеров,когда люди доказывают, что эти модели, хотя и продвигаются к лучшему рассуждению, по-прежнему далеки от идеала.
Важно отметить, что эти модели ИИ продолжают не справляться с адаптацией.
Другими словами, когда их сверхчеловеческая память (они знают много о многих вещах) недоступна, чтобы спасти положение, они терпят неудачу, до такой степени, что модели o1 не предлагают никакого значительного преимущества над предыдущим поколением передовых технологий, Claude 3.5 Sonnet, когда дело доходит до решения задач абстрактного рассуждения в тестах ARC-AGI.
Приобретение навыков, или получение новых возможностей в условиях неопределенности, является ключевым признаком человеческого интеллекта, который ИИ пока далеко не достиг, даже для более продвинутых моделей, таких как o1 от OpenAI.
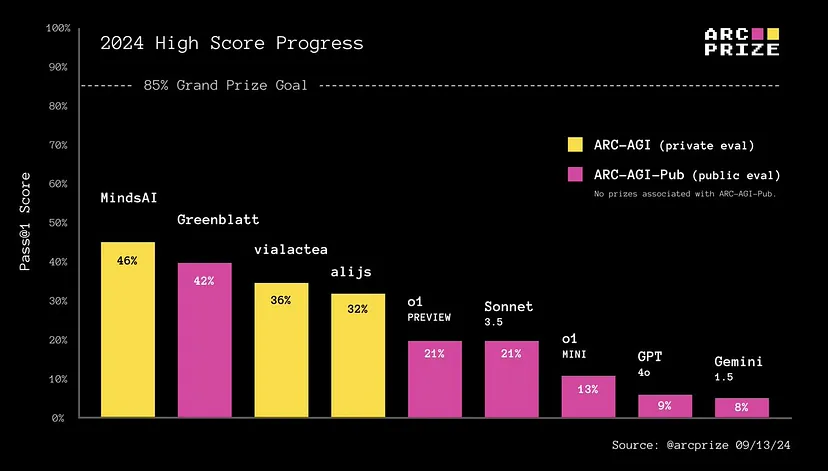
Другими словами, наши текущие лучшие системы рассуждений начинают проявлять признаки рассуждения в области «известного известного», т.е. рассуждения на основе известных данных, но не лучше предыдущих поколений, когда дело доходит до обобщения в полностью неизвестных средах. Проще говоря, они не могут рассуждать в областях без предварительных знаний.
Так что подразумевают, когда намекают на то, что «рассуждение ИИ было освоено»? Позвольте объяснить, что они подразумевают:
Высокомерие.
Тем не менее, интеллект — это очень философская тема, которая вызывает разногласия среди очень умных людей, поэтому я не хочу углубляться в нее. На самом деле, это не самая большая проблема: это энергоэффективность.
Неприличные цифры.
Все гипермасштабные компании рассматривают возможность создания центров обработки данных мощностью 1 ГигаВатт (GW) в течение следующих двух лет. Для справки, каждый из этих гигацентров будет потреблять столько же энергии, сколько и Сан-Франциско.
- Реализуется проект дата-центра Project Stargate от Microsoft, о котором ходят слухи. Они только что объявили о партнерстве с BlackRock и другими инвесторами на сумму 30 миллиардов долларов, что в итоге станет, к слову, 100 миллиардами долларов после привлечения долгового финансирования.
- Amazon купила атомную электростанцию мощностью 960 МВт у Talen Energy за 650 миллионов долларов, хотя планы по увеличению мощности займут время. Аналогичным образом, всего несколько дней назад Microsoft согласилась на сделку по повторному открытию Трехмильного острова, места самого худшего коммерческого ядерного инцидента в истории США, и закупке как можно больше энергии от станции мощностью 880 МВт в течение следующих 20 лет, начиная с 2028 года.
- Google планирует два отдельных проекта дата-центров мощностью ГигаВатт в Айове и Небраске, которые будут запущены в 2026 и 2025 годах соответственно.
- Илон Маск заявил, что увеличит установленную базу своего дата-центра Colossus в два раза до 200 000 эквивалентов H100 в течение следующих нескольких месяцев и недавно привлек 6 миллиардов долларов.
- Ларри Эллисон, генеральный директор Oracle, признал одобрение плана по строительству дата-центра мощностью 1 ГВт с использованием трех малых ядерных реакторов и даже упомянул о трехсторонней встрече с Илоной и Дженсеном, на которой они оба просили последнего о «большее количество GPU».
- Даг Бергум и Джош Тейген, губернатор и директор Департамента торговли Северной Дакоты соответственно, признали встречи с руководителями крупных технологических компаний, предлагающими идею дата-центра мощностью от 5 до 10 ГВт. Для справки, общая доступная вычислительная мощность Microsoft Azure составляет около 5 ГВт.
Дата-центр мощностью 1 ГигаВатт с эквивалентом GPU H100 будет обладать невероятной вычислительной мощностью.
- В нем будет 714 000 GPU, каждый из которых имеет пиковую производительность FLOP на уровне 3 958 ТераFLOP (TFLOP) при точности fp8 (1 байт на параметр, что может скоро стать нормой) или 3 958 триллионов математических операций в секунду.
- С пиковым общим вычислительным потенциалом 2,83×10²¹ FLOP, или 2,8 ЗеттаFLOP (2,8 секстиллионов математических операций в секунду).
Умопомрачительные цифры. Но какова цена?
С точки зрения денег, совокупные капитальные инвестиции, по 25 000 долларов на штуку, составят 17,85 миллиарда долларов. Предполагая 35% использования MFU (коэффициент, при котором фактически используется вычислительная мощность каждого GPU, что также влияет на то, сколько энергии потребляет этот GPU), ежедневные расходы при среднем тарифе на электроэнергию в США 0,083 €/КВтч составят 697 200 долларов.
И здесь все становится совершенно неразумно. Эффективность вычислений этого суперкомпьютера ужасно низка по сравнению с самым эффективным компьютером в мире: людьми.
Этот суперкомпьютер будет иметь эффективность вычислений, измеряемую в FLOP/Ватт, 2,8 триллионов FLOP / Ватт. Если быть точным, каждое ваттное потребление этого кластера допускает 2,8×10¹² математических расчетов.
Человеческий мозг требует около 20 ватт для обработки числа FLOP, которое, хотя это значение варьируется, как правило, колеблется между 1 ПетаFLOП и 1 ЭксaFLOП, то есть от одного квадриллиона до одного квинтиллиона FLOP.
Но даже если мы возьмем нижнюю оценку, человеческий мозг генерирует {10¹⁵ FLOP / 20 Ватт = 50 триллионов FLOP на Ватт}, что в 25 раз более эффективно, чем этот суперкомпьютер (если мы возьмем верхнюю оценку, человеческий мозг оказывается в 17 000 раз более эффективным, а это астрономическая разница).
Теперь я не говорю, что мы должны стремиться к человеческой эффективности как предпосылке для AGI или сверхинтеллекта (хотя некоторые исследователи, несомненно, разделят этот взгляд), но меня поражает то, что мы видим эти цифры и просто отворачиваемся.
И это еще не все проблемы; мы даже не знаем, как масштабировать эти дата-центры!
Неотвеченный вопрос.
Конвейеры обучения ИИ являются синхронными из-за проблем с конвергенцией, а это означает, что эти кластеры разделены на более мелкие модули с графическим процессором, которые обучают модели отдельно, но должны делиться «своими знаниями» для синхронного построения общей модели, что приводит к ужасным задержкам при сбое графического процессора (отставание).
Например, модели Llama 3.1 от Meta потребовали до трех раз больше времени на обучение, чем теоретическая стоимость, из-за этих проблем (17 против 54 дней).
И, учитывая, что более крупные кластеры будут сталкиваться с более серьезными проблемами и задержками, почему мы не можем просто обучать эти модели асинхронно?
Не вдаваясь в подробности, закон Амдала доказывает, что если мы не найдём способ обучать эти алгоритмы асинхронно, то вскоре увидим, что коэффициент использования вычислительных мощностей модели (Model FLOP Utilization, MFU) будет едва достигать 10%, добавляя тысячи новых графических процессоров в кластер лишь для получения незначительных результатов, поскольку последовательные (непараллелизуемые) нагрузки мешают нормальному масштабированию.
Например, учитывая, что мы едва можем запустить кластер на 16 000 графических процессоров, такой как Meta, скорость загрузки которого превышает 40%, кластер на 700 тыс. легко упадет ниже 10%, что может означать, что 90% всего кластера простаивает в любой момент времени.
Нас не останавливает эта суровая реальность, и мы продолжаем двигаться вперед. Потому что мы самонадеянны.
Возможно, мы сильно ошибаемся.
Рассмотрев технологии и энергоэффективность, я искренне считаю, что мы не только чрезвычайно самонадеянны, но и вопиюще неправы, и нам нужны прорывы в алгоритмах.
Улучшение интеллектуальности модели при одновременном повышении ее устойчивости не является чем-то приятным; это необходимое условие успеха.
Тем временем:
- Мы не завоевали интеллект, как это показывают маркетинговые трюки,
- у нас нет ощутимого спроса со стороны общества на продукты с искусственным интеллектом,
- у нас нет эффективных средств масштабирования, и, что еще хуже, мы игнорируем возможные изменения архитектуры, которые позволят улучшить масштабирование,
- и у нас даже нет достаточных ресурсов для обеспечения будущего спроса на искусственный интеллект.
Тем не менее, наша приверженность вычислительной технике непоколебима и безгранична, почти ревностна.
Почему?
Конечно, потому что мы самонадеянны.





Обсуждение закрыто.