
Углубленный анализ самой ожидаемой модели искусственного интеллекта следующего поколения
Эта супердлинная статья — часть обзор, часть исследование — посвящена GPT-5.
Она также касается гораздо больших тем.
- Здесь речь идет о том, чего мы можем ожидать от моделей ИИ следующего поколения.
- Речь идет о новых интересных функциях, которые появляются на горизонте (например, о рассуждениях и агентах). Речь идет о технологии GPT-5 и продукте GPT-5.
- Речь идет о давлении бизнеса на OpenAI со стороны конкурентов и технических ограничениях, с которыми сталкиваются его инженеры.
- Она обо всех этих вещах — вот почему в ней 14 000 слов.
Вы, вероятно, задаетесь вопросом, почему вам стоит потратить следующий час на чтение этой мини-книги, если вы уже слышали утечки и слухи о GPT-5. Вот ответ:
Разрозненная информация бесполезна без контекста; большая картина становится ясной только тогда, когда всё собрано в одном месте.
Прежде чем мы начнем, давайте вкратце расскажем о череде успехов OpenAI и о том, почему огромное ожидание выхода GPT-5 оказывает на них давление.
Четыре года назад, в 2020 году, GPT-3 шокировал техническую индустрию. Компании, такие как Google, Meta и Microsoft, поспешили бросить вызов лидерству OpenAI. Они сделали это (например, LaMDA, OPT, MT-NLG), но с двухлетней задержкой. К началу 2023 года, после успеха ChatGPT, OpenAI был готов выпустить GPT-4. И снова компании бросились следовать за ними. Через год у Google есть Gemini 1.5, у Anthropic — Claude 3.5, а у Meta — Llama 3.2.
OpenAI вскоре выпустит GPT-5 — но насколько далеко находятся его конкуренты снова?
Разрыв сужается, и гонка вновь зашла в тупик, поэтому все — клиенты, инвесторы, конкуренты и аналитики — смотрят на OpenAI, с нетерпением ожидая, смогут ли они в третий раз совершить скачок, который продвинет их на год вперед.
Вот это и есть неявное обещание GPT-5; надежда OpenAI остаться влиятельными в борьбе с самыми мощными технологическими компаниями в истории. Представьте разочарование в мире ИИ, если ожидания не оправдаются (что, по мнению инсайдеров, таких как Билл Гейтс, может произойти).
Вот такая яркая и ожидающая обстановка, в которой формируется GPT-5. Один неверный шаг — и все бросятся осуждать OpenAI. Но если GPT-5 превзойдет наши ожидания, он станет ключевым элементом в головоломке ИИ на следующие несколько лет, не только для OpenAI и его довольно зеленой бизнес-модели, но и для людей, которые за это платят — инвесторов и пользователей. Если это произойдет, Gemini 1.5, Claude 3.5 и Llama 3.2 вернутся в дискурсивную безвестность.
Такова предыстория. Давайте перейдем к статье.
Для ясности я разделил её на четыре части.
- Во-первых, я написал несколько мета-материалов о GPT-5: будут ли у других компаний ответ на GPT-5, сомнения в нумерации (то есть GPT-4.5 против GPT-5) и то, что я назвал “ловушкой бренда GPT”. Вы можете пропустить эту часть, если просто хотите узнать о самом GPT-5.
- Во-вторых, я собрал список информации, данных, прогнозов, утечек, подсказок и других доказательств, раскрывающих детали о GPT-5. Этот раздел сосредоточен на цитатах из источников (добавляя мою интерпретацию и анализ, когда это неясно), чтобы ответить на два вопроса: Когда выйдет GPT-5 и насколько он будет хорош?
- В-третьих и в-четвертых, я исследовал — следуя “крошкам” — чего мы можем ожидать от GPT-5 в областях, о которых мы всё ещё ничего не знаем официально: законы масштабирования (данные, вычисления, размер моделей) и алгоритмические прорывы (рассуждение как o1, агенты, мультимодальность и т. д.). Это всего лишь информированная спекуляция — так что это самая интересная часть.
Я добавил сводки в конце большинства разделов. Если вы устанете от чтения, я рекомендую сначала ознакомиться с ними!
Часть 1: Немного информации о GPT-5
Класс моделей GPT-5
В период с марта 2023 по январь 2024 года, когда вы говорили о современном ИИ-интеллекте или способностях в различных дисциплинах, вы говорили о GPT-4. Ни с чем другим это не могло сравниться. Модель OpenAI была самостоятельной.
С февраля 2024 года ситуация изменилась. Google Gemini (1.0 Ultra и 1.5 Pro), Anthropic Claude (3 Opus и 3.5 Sonnet) и Meta Llama 3.x относятся к моделям класса GPT-4 (GPT-4 и GPT-4o относятся к той же категории).
Претенденты на этот долгожданный титул давно назрели, но, в конце концов, они здесь. Сильные и слабые стороны варьируются в зависимости от того, как вы их используете, но с точки зрения производительности все три находятся на одном уровне. Эта новая реальность заставила усомниться в лидерстве OpenAI.
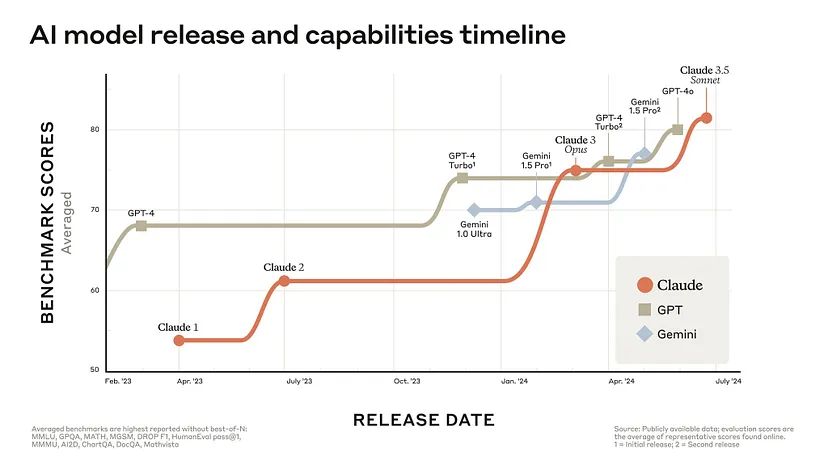
Но мы не должны забывать, что между OpenAI и остальными есть годовой разрыв; по меркам прогресса ИИ, GPT-4 — это старая модель.
Трудно утверждать, что скромные итеративные улучшения, которые разделяют версии GPT-4 (GPT-4 Turbo и GPT-4o), могут сравниться с совершенно новой передовой моделью. “Скелет” GPT-4 — архитектурные детали, которые так явно отделяют его по качеству от GPT-3 — имеет возраст 1.5 года. Это плохо сказывается на Gemini, Claude и Llama, которые, безусловно, используют самые свежие исследования на более глубоких уровнях (например, архитектурные изменения, алгоритмические улучшения и т.д.), чем GPT-4 может предложить просто обновлением тонкой настройки или учебных данных.
Интересный вопрос заключается в следующем:
Сохранила ли OpenAI свое преимущество в тени, создавая GPT-5? Или ее конкуренты наконец-то сократили разрыв?
Есть вероятность, что Google, Anthropic и Meta предложили нам все, что у них есть; что Gemini 1.5, Claude 3.5 и Llama 3.2 — это лучшее, чего они могут достичь. Я не думаю, что это так (пропущу Meta здесь, потому что они находятся в уникальной ситуации, которую следует анализировать отдельно).
Давайте начнем с Google.
Google анонсировала Gemini 1.5 через неделю после выпуска Gemini Advanced (с бэкендом 1.0 Ultra). Они лишь приоткрыли занавес того, на что способна Gemini 1.5; они анонсировали промежуточную версию 1.5 Pro, которая уже находится на уровне GPT-4, но я не думаю, что это лучшее, что у них есть. Я верю, что Gemini 1.5 Ultra готова (и была готова в течение месяцев).
Если они еще не выпустили её, то потому что усвоили урок, которым OpenAI пользуется с ранних этапов: выгодное время для релиза имеет принципиальное значение для успеха. Соревнование в области генеративного ИИ слишком широко, чтобы игнорировать эту часть.
Понимая, что между 1.0 Pro и 1.0 Ultra существует большой разброс, разумно предположить, что Gemini 1.5 Ultra будет значительно лучше, чем 1.5 Pro (хотя Google еще не улучшил часть с именованием). Но насколько хорошей будет Gemini 1.5 Ultra? На уровне GPT-5? Мы не знаем, но с учётом оценок 1.5 Pro это возможно. (Также возможно, что Google сразу перейдет к Gemini 2.0.)
То, что Gemini 1.0 находится на уровне GPT-4, не случайно — это не следствие того, что они наткнулись на стену или признак ограниченности Google, а заранее запланированный шаг, чтобы показать миру, что они тоже могут создать такой ИИ (напоминаю, что команда, строящая модели, не та команда, которая отвечает за маркетинг, в чем Google часто терпит неудачи).
Ситуация с Anthropic мне не так ясна. Они более сдержанны в отношениях с прессой, чем Google и OpenAI, но у меня нет причин исключать их, учитывая, что производительность Claude 3.5 немного превышает GPT-4, и трудно поверить, что это случайность.
Еще один ключевой момент в пользу Anthropic — это то, что компания была основана в 2021 году. Сколько времени нужно стартапу мирового уровня в области ИИ, чтобы начать конкурировать на высшем уровне? Партнёрства, инфраструктура, оборудование, время на обучение и т.д. требуют времени, и Anthropic только начинала свою работу, когда OpenAI начала обучение GPT-4. Claude 3 и 3.5 были первым серьёзным усилием Anthropic, поэтому я не удивлюсь, если Claude 4 выйдет раньше, чем ожидалось, и сможет соответствовать тому, чего может достичь OpenAI с GPT-5.
Я вижу четкую закономерность.
С каждым новым поколением передовых моделей (сначала уровня GPT-3, затем уровня GPT-4, следующее — уровень GPT-5) разрыв между лидером и остальными сокращается. Причина очевидна: ведущие компании в области ИИ научились надежно создавать эту технологию. Создание лучших в своем классе больших языковых моделей (LLM) — это решенная проблема. Это больше не секрет OpenAI. В начале у них было преимущество, потому что они поняли то, что другим еще не удалось, но теперь другие наверстали.
Даже если компании умеют хорошо защищать свои коммерческие секреты от шпионов и утечек, технологии и инновации в конечном итоге стремятся к тому, что возможно и что можно себе позволить. Модели уровня GPT-5 могут иметь определённую степень гетерогенности (как это происходит с классом GPT-4), но направление, в котором они все движутся, одинаково.
Если я прав, это снижает значимость самого GPT-5 — именно поэтому я считаю, что этот анализ из 14,000 слов должен восприниматься более широко, чем просто как предварительный обзор GPT-5 — и переводит фокус на весь класс моделей. Это хорошо.
Вывод: Я верю, что Anthropic Claude 4.0, Google Gemini 2.0 и Meta Llama 4.0 будут находиться на уровне OpenAI GPT-5.
GPT-5 или GPT-4.5?
В начале марта появились слухи о том, что GPT-4.5 утекла (анонс, а не веса модели). Поисковые системы успели зафиксировать новость до того, как OpenAI её удалило. На веб-странице говорилось, что “срез знаний” (насколько долго модель знает о состоянии мира) составляет июнь 2024 года. Это означает, что гипотетический GPT-4.5 будет обучаться до июня, а затем пройдет месячный процесс тестирования на безопасность, установки ограничений и проверки, что задержит выпуск до конца 2024 года (через два месяца).
Если это правда, значит ли это, что GPT-5 не выйдет в этом году? Возможно, но не обязательно.
Важно помнить, что такие названия, как GPT-4, GPT-4.5, GPT-5 (или что-то совершенно другое, например, o1!) являются условными обозначениями для уровня возможностей, который OpenAI считает достаточным для получения определенного номера версии. OpenAI постоянно улучшает свои модели, исследует новые научные направления, проводит тренировки с различными уровнями вычислений и оценивает контрольные точки модели. Создание новой модели — это не простая и прямая задача, а требует множества проб и ошибок, настройки деталей и “YOLO-тестов”, которые могут дать неожиданные хорошие результаты.
После всех экспериментов, когда они почувствуют, что готовы, они проводят большую тренировку. Как только модель достигает уровня “достаточно хорошо”, они выпускают её под наиболее подходящим названием. Если бы они назвали GPT-4.5 GPT-5 или наоборот, мы бы не заметили.
Этот поэтапный процесс с контрольными точками также объясняет, почему Gemini 1.5 и Claude 3.5 могут немного превышать возможности GPT-4, не означая, что существует стена для LLM.
Все источники, которые я приведу ниже, говоря о “выпуске GPT-5”, возможно, говорят, не осознавая этого, о GPT-4.5 или о чем-то новом с другим названием (некоторые из этих цитат предшествуют анонсу OpenAI o1, так что это может быть так). Возможно, утечка GPT-4.5, которая ставит срез знаний на июнь 2024 года, станет GPT-5 после некоторых улучшений (возможно, они пытались достичь уровня GPT-4.5, но не смогли и решили отложить выпуск).
Эти решения зависят от внутренних результатов и действий конкурентов (возможно, OpenAI не ожидала, что Claude 3.5 станет предпочтительной моделью для публики в марте и решила отложить выпуск GPT-4.5 по этой причине).
Вот одна веская причина считать, что не будет выпуска GPT-4.5: не имеет смысла делать версии x.5, когда конкуренция такова и scrutiny такой интенсивный (даже если Сэм Альтман говорит, что хочет удвоить усилия по итеративному развёртыванию, чтобы избежать шоков для мира и дать нам время адаптироваться и так далее).
Люди подсознательно воспринимают каждую новую крупную версию как “следующую модель”, независимо от номера, и будут проверять её в соответствии со своими ожиданиями (думаю, именно поэтому OpenAI назвала o1 новой семейством, а не GPT-5, потому что это слишком похоже на GPT-4o). Если пользователи почувствуют, что это не достаточно хорошо, они будут задаваться вопросом, почему OpenAI не подождала. Если им это понравится, тогда OpenAI задумается, не стоило ли называть это x.0 вместо x.5.
Не все соответствует желаниям клиентов, но генеративный ИИ сейчас больше индустрия, чем научная область. OpenAI следует сосредоточиться на модели GPT-5 и сделать её хорошей.
Тем не менее, есть исключения.
OpenAI выпустила модель GPT-3.5, но если подумать, это было малозаметное изменение (позже оно было затмеваемо ChatGPT). Они не делали шума вокруг этого, как с GPT-3, GPT-4, GPT-4o и o1 — или даже DALL-E и Sora.
Другой пример — Gemini 1.5 Ultra, выпущенный через неделю после Gemini 1.0 Ultra. Google хотела нагнетить свою победу над GPT-4, выпустив два последовательных релиза, превышающих лучшую модель OpenAI. Это провалилось — Gemini 1.0 Ultra не была лучше GPT-4 (люди ждали большего, не хитрой демонстрации), а Gemini 1.5 была затмевана Sora, которую OpenAI выпустила через несколько часов позже (Google всё еще многому должна научиться у маркетинговой тактики OpenAI).
Так что, OpenAI нужно иметь хорошую причину для выпуска GPT-4.5.
Вывод: Номенклатура условна. В любом случае, я не думаю, что OpenAI пойдет на выпуск GPT-4.5 и вместо этого выпустит сразу GPT-5.
Ловушка для бренда GPT
Последнее, что я хочу упомянуть в этом разделе, — это ловушка GPT.
В отличие от других компаний, OpenAI сильно ассоциировала свои продукты с акронимом GPT, который теперь является не только техническим термином (как изначально), но и брендом с неким престижем и силой, от которых трудно отказаться.
GPT, или Генеративный Предобученный Трансформер, — это конкретный тип архитектуры ИИ, которая может или не может пережить новые прорывы в исследовании. Может ли GPT избежать “авторегрессионной ловушки”? Можете ли вы привнести рассуждения в GPT или улучшить его до уровня агента? Неясно.
Мой вопрос таков: будет ли OpenAI продолжать называть свои модели GPT, чтобы сохранить мощный бренд, с которым большинство людей ассоциируют ИИ, или они останутся строгими и перейдут на что-то другое, когда техническое значение исчерпается более совершенными вещами? Если OpenAI будет придерживаться этого бесценного акронима (как предполагают регистрации товарных знаков), разве они не подрывают собственное будущее, закрепляя его в прошлом?
OpenAI рискует позволить людям ошибочно поверить, что они взаимодействуют с другим чат-ботом, когда у них в руках может быть мощный агент.
(Я написал эти слова выше в апреле 2024 года: теперь мы знаем, что OpenAI назвала свою последнюю модель o1, потому что не считает ее частью семейства GPT, что указывает на то, что они не так привязаны к ловушке бренда GPT, как я изначально думал. Тем не менее, я не думаю, что этот трюк сработает с GPT-5. Люди — мир — ожидают название GPT-5 от OpenAI, и OpenAI должна это предоставить.)
Вывод: OpenAI должна решить, стоит ли оставаться с мощным брендом GPT или двигаться вперед с чем-то новым, чтобы люди могли оценить, с чем они взаимодействуют, когда это более мощно, чем чат-бот.
Часть 2: Все, что мы знаем о GPT-5
Когда OpenAI выпустит GPT-5?
18 марта Лекс Фридман провел интервью с Сэмом Альтманом. Одной из деталей, которую он раскрыл, был срок выпуска GPT-5. Фридман спросил: «Итак, когда же выйдет GPT-5?» На что Альтман ответил: «Я не знаю; это честный ответ».
Я верю в его честность настолько, что считаю возможными разные интерпретации его неоднозначного «Я не знаю». Думаю, он точно знает, что хочет, чтобы OpenAI сделала, но неуверенность, присущая жизни, позволяет ему честно сказать, что не знает.
Если Альтман знает то, что нужно знать, он может не говорить больше, потому что, во-первых, они все еще решают, стоит ли выпускать GPT-4.5, во-вторых, они измеряют расстояние с конкурентами, и, в-третьих, он не хочет раскрывать точную дату, чтобы не дать конкурентам возможность каким-то образом затмить запуск, как это происходит постоянно с Google.
Затем он колебался, отвечая, выйдет ли GPT-5 в этом году, но добавил: «Мы выпустим потрясающую новую модель в этом году; я не знаю, как мы ее назовем». (Он явно имел в виду o1.)
Я думаю, это неясность объясняется моими аргументами выше в разделе «Название GPT-5 произвольно». Альтман также сказал, что у них есть «много других важных вещей для выпуска сначала». Некоторые вещи, к которым он мог иметь в виду: публичный Sora и движок Voice (да), автономный веб/рабочий ИИ-агент, лучший интерфейс/опыт ChatGPT (да), поисковая система (да), модель рассуждений/математики (да).
Таким образом, создание GPT-5 — это приоритет, но его выпуск — нет.
Альтман также сказал, что OpenAI ранее упустила момент для «удивительных обновлений для мира» (например, первая версия GPT-4). Это может пролить свет на причины его неопределенности относительно даты выхода GPT-5. Он добавил: «Может быть, нам стоит подумать о том, чтобы выпустить GPT-5 по-другому». Это можно интерпретировать как неясный комментарий, но я думаю, это помогает объяснить колебания Альтмана, чтобы сказать что-то вроде: «Я знаю, когда мы выпустим GPT-5, но не скажу вам», что довольно справедливо.
Возможно, способ, которым они собираются выпустить GPT-5 иначе, чтобы не шокировать мир, заключается в тестировании его частей (например, новая математика/рассуждения с o1, генерация видео с Sora, речь с Advanced Voice и т.д.) в реальных условиях, прежде чем объединить их в единое целое для гораздо более мощной базовой модели. В противном случае это было бы неответственно и не соответствовало бы словам Альтмана.
Давайте рассмотрим другие источники.
19 марта, на следующий день после интервью Фридмана и Альтмана, Business Insider опубликовал статью с заголовком «OpenAI, как ожидается, выпустит “значительно лучший” GPT-5 для своего чат-бота в середине года, говорят источники», что прямо противоречит тому, что сказал Альтман накануне. Как может источник, не относящийся к OpenAI, знать дату, если сам Альтман не знает? Как может GPT-5 выйти в середине года, если у OpenAI еще так много вещей, которые нужно выпустить в первую очередь? Информация противоречива. Вот что написал Business Insider:
Генеративная ИИ-компания под руководством Сэма Альтмана на пути к выпуску GPT-5 где-то в середине года, вероятно, летом, согласно двум людям, знакомым с деятельностью компании [личности подтверждены Business Insider]. … OpenAI все еще обучает GPT-5, сказал один из знающих людей. После завершения обучения модель будет сначала проходить внутренние испытания безопасности и дальнейшее «тестирование на уязвимости»…
Таким образом, обучение GPT-5 все еще продолжалось 19 марта (единственный факт из статьи, а не предсказание). Давайте сделаем оптимистичный предположительный расчет и скажем, что обучение завершилось в апреле 2024 года, и с тех пор OpenAI проводит тестирование на безопасность и проверку. Как долго это будет продолжаться, прежде чем они будут готовы к развертыванию? Давайте снова сделаем оптимистичный расчет и скажем «так же, как с GPT-4» (предполагая, что GPT-5 более сложен, как мы увидим в следующих разделах, это безопасная нижняя граница). GPT-4 завершило обучение в августе 2022 года, а OpenAI анонсировала его в марте 2023 года. Это семь месяцев на обеспечение безопасности. Но помните, что Bing Chat от Microsoft уже использовал GPT-4 «под капотом». Bing Chat был анонсирован в начале февраля 2023 года. Так что это полгода.
В целом, самые оптимистичные оценки указывают на то, что выпуск GPT-5 может быть отсрочен до октября 2024 года — это уже очень близко! — в лучшем случае. Это за месяц до выборов в США. Наверняка OpenAI не так безрассудна, учитывая историю AI-руководимой политической пропаганды.
Не могло ли быть, что «GPT-5 выйдет где-то в середине года» — это ошибка Business Insider и речь идет о OpenAI o1 вместо этого?
Эта точка зрения согласует всю информацию, которую мы проанализировали до сих пор: она согласует «Я не знаю, когда выйдет GPT-5» Альтмана и «у нас есть много других важных вещей, которые нужно выпустить сначала». Это также соответствует акценту на пошаговом внедрении и угрозе, которую «шокирующая» новая модель может представлять для выборов.
Учитывая всю эту информацию (включая противоречивые части, которые становятся логичными, как только мы понимаем, что «GPT-5» — это произвольное название и что источники, не относящиеся к OpenAI, могут путать названия предстоящих релизов), моя ставка такова: GPT-5 на 100% выйдет после выборов. OpenAI выпустит что-то новое в ближайшие месяцы, но это не будет самым крупным релизом, о котором говорит Альтман, который ожидается в этом году. (Недавние события предполагают, что возможен еще более ранний сюрприз.)
Вывод: GPT-5 не может выйти раньше четвертого квартала 2024 года, но, скорее всего, будет отложен до первого-второго квартала 2025 года.
Насколько хорош будет GPT-5?
Вот вопрос, которого все ждали.
Ценность этого раздела двояка: во-первых, это сборник источников, которые вы могли пропустить. Во-вторых, это анализ и интерпретация информации, который может пролить свет на то, чего ожидать.
На протяжении нескольких месяцев Алтман намекал на свою уверенность в улучшении GPT-5 по сравнению с существующими ИИ. В начале 2024 года, в частном разговоре, состоявшемся во время Всемирного экономического форума в Давосе, Алтман рассказал корейским СМИ Maeil Business Newspaper и другим новостным источникам следующее (переведено с помощью Google): «GPT-2 был очень плох. GPT-3 был довольно плох. GPT-4 был довольно плох. Но GPT-5 будет хорошим». Он также сказал Лексу Фридману, что GPT-4 «в какой-то степени ужасен» и что GPT-5 будет «умнее», не только в одной категории, а в целом.
Люди, близкие к OpenAI, также говорили размыто. Ричард Хэ, через Хауи Сю, сказал: «Большинство ограничений GPT-4 будут устранены в GPT-5», а неназванный источник сказал Business Insider, что «[GPT-5] действительно хорош, как материально лучше». Вся эта информация вполне хороша, но также тривиальна, неопределенна или даже ненадежна (можем ли мы в данный момент доверять источникам Business Insider?).
Тем не менее, есть одна вещь, которую Алтман сказал Фридману, которую я считаю самым важным пунктом данных о интеллекте GPT-5. Вот что он сказал:
«Я ожидаю, что разница между 5 и 4 будет такой же, как между 4 и 3».
Это утверждение существенно более информативно, чем другие. Если оно звучит загадочно, это связано с тем, что то, что оно говорит, не о абсолютном уровне интеллекта GPT-5, а о его относительном уровне интеллекта, который может быть сложнее для анализа.
В частности, это означает: GPT-3 → GPT-4 = GPT-4 → GPT-5.
Для интерпретации этого «уравнения» нам нужны технические средства, чтобы его разобрать. Нам также нужно знать много о GPT-3 и GPT-4. Мне нужно только предположить, что Алтман знает, о чем говорит — он понимает, что означают эти дельты — и что он уже знает примерный уровень интеллекта GPT-5, даже если он еще не готов.
Исходя из этого, я выдвинул три интерпретации (для ясности я использовал только номера моделей, без «GPT»).
Первая интерпретация заключается в том, что дельты 4–5 и 3–4 относятся к сопоставимым скачкам в оценках по бенчмаркам, что означает, что 5 будет значительно умнее 4, так же как 4 был значительно умнее 3 (это начинается сложно, потому что общепризнано, что оценки неэффективны, но давайте временно отложим это). Это, безусловно, тот результат, которым люди были бы рады знать, что по мере улучшения моделей подъем по бенчмаркам становится гораздо сложнее.
Так сложно, что я начинаю сомневаться, возможно ли это вообще. Не потому, что ИИ не может стать таким интеллектуальным, а потому, что такой интеллект сделает наши человеческие измерительные шкалы слишком короткими — тесты будут слишком легкими для GPT-5.
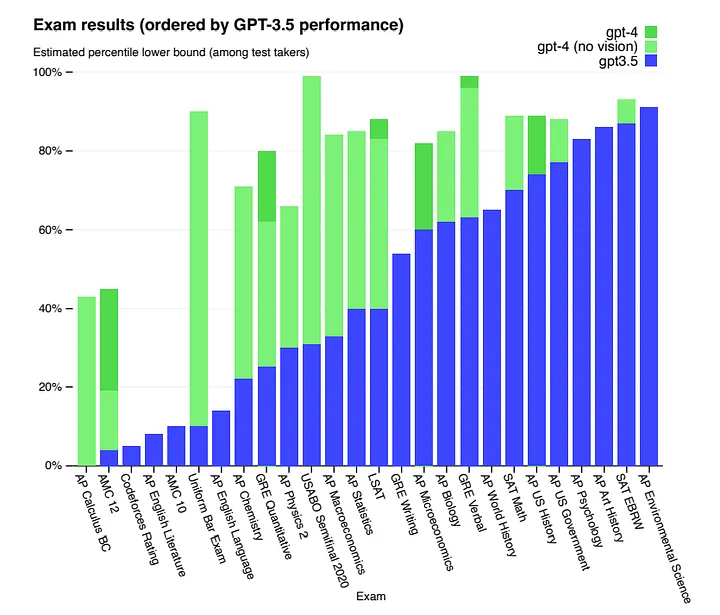
Технический отчет по GPT-4
Этот график выше сравнивает 4 с 3.5 (3 был бы ниже). В некоторых областях 4 не улучшилась сильно, но в других она настолько лучше, что уже рискует сделать оценки бессмысленными из-за слишком высоких значений. Даже если бы мы приняли, что 5 не будет лучше в абсолютно всем, в тех областях, где она будет лучше, она превзойдет предельные значения, которые могут предложить бенчмарк-показатели. Это делает невозможным для 5 достичь дельты от 4, равную 3–4. По крайней мере, если мы будем использовать эти бенчмарки.
Если мы предположим, что Алтман считает более сложные бенчмарки (например, SWE-bench или ARC), где результаты моделей GPT-3 и GPT-4 очень плохи (GPT-4 на SWE-bench, GPT-3 на ARC, GPT-4 на ARC), тогда наличие показателя дельты, аналогичного предыдущему, было бы неудовлетворительным. Если вместо этого взять экзамены, созданные для людей (например, SAT, Bar, AP), нельзя доверять тому, что данные для обучения GPT-5 не были изменены.
Вторая интерпретация предполагает, что дельта относится к нелинейным законам «экспоненциального» масштабирования (увеличение размера, данных, вычислительных мощностей), а не к линейному увеличению производительности.
Это подразумевает, что 5 продолжает кривые, очерченные ранее моделями 2, 3 и 4, независимо от того, какую производительность это дает. Например, если 3 имеет 175 миллиардов параметров, а 4 — 1,8 триллиона, то 5 будет иметь около 18 триллионов. Но количество параметров — это только один фактор в подходе к масштабированию — тем более теперь, когда новый набор законов масштабирования будет доминировать в ландшафте отсюда и далее — так что дельта может включать все остальное: сколько вычислительной мощности они используют, сколько данных для обучения они подают модели и т. д.
Это более безопасное утверждение от Алтмана (OpenAI контролирует эти переменные) и более разумное (всплывающие возможности требуют новых бенчмарков, для которых предыдущие данные отсутствуют, что делает сравнение 3→4 и 4→5 невозможным). Однако Алтман говорит, что ожидает эту дельту, что подразумевает, что он не знает точно, что было бы странно.
Третья возможность состоит в том, что дельта Алтмана относится к восприятию пользователями, т.е. пользователи будут воспринимать 5 как лучшее, чем 4, в той же степени, в какой они воспринимали 4 как лучшее, чем 3 (спросите активных пользователей, и вы узнаете, что ответ будет «очень сильно»). Это смелое утверждение, потому что Алтман не может знать, что мы будем думать, но он может исходить из опыта; вот что он почувствовал из первоначальных оценок, и он просто делится своей анекдотической оценкой.
Если эта интерпретация верна, то мы можем заключить, что GPT-5 окажется впечатляющим. Если это действительно так для людей, которые чаще всего работали с предыдущими версиями — которые также имеют самые высокие ожидания и у которых новизна технологии наименее актуальна.
Если я буду щедрым и мне придется угадать, какая интерпретация наиболее верна, я выберу эту. Если я не буду щедрым, есть четвертая интерпретация:
Алтман просто разряжает ожидания относительно следующего продукта своей компании. OpenAI в прошлом уже оправдывал ожидания, но агрессивные маркетинговые тактики всегда присутствовали (например, выпуск Sora за несколько часов после того, как Google выпустил Gemini 1.5). Мы можем по умолчанию отдать предпочтение этому варианту, чтобы быть в безопасности, но я верю, что в трех вышеописанных версиях есть доля правды, особенно в третьей.
Тем не менее, это поверхностный способ оценить, насколько хорошим может быть GPT-5. В следующем разделе рассматривается более целостный способ понять, чего хочет достичь OpenAI и как это влияет на GPT-5.
Вывод: либо GPT-5 будет значительно лучше, чем GPT-4, либо OpenAI потеряет внимание публики. Тем не менее, я верю, что многое из того, что говорит Алтман, движимо его необходимостью получить деньги и одобрение правительства.
Как цели OpenAI формируют GPT-5
Прежде чем углубляться в территорию спекуляций, позвольте мне поделиться тем, что я считаю правильной основой для понимания того, чем может и чем не может быть GPT-5, то есть как отличить обоснованные спекуляции от заблуждений. Это общий взгляд, который поможет понять всю стратегию OpenAI в области ИИ.
Официальной целью OpenAI является AGI (искусственный общий интеллект). Помимо AGI, у OpenAI есть две «неофициальные цели» (инструментальные цели, если хотите), более конкретные и актуальные, которые являются настоящими узкими местами на пути к следующему шагу (в техническом смысле; с точки зрения продукта есть и другие соображения, такие как «Создавать то, что нужно людям»).
Эти две цели — это увеличение возможностей и снижение затрат. Все, что мы можем гипотетически предположить о GPT-5, должно соответствовать необходимости найти баланс между этими двумя целями.
OpenAI всегда может бездумно увеличивать возможности (если только их исследователи и инженеры знают, как это сделать), но это может повлечь неприемлемые расходы на Azure Cloud, что может повредить партнерству с Microsoft (которое уже не так эксклюзивно, как раньше). OpenAI не может позволить себе стать источником убытков. DeepMind в начале своего пути был денежной ямой Google, но это оправдывалось «во имя науки». OpenAI сосредоточен на бизнесе и продуктах, поэтому им нужно зарабатывать прибыль.
Они всегда могут снижать затраты (разными способами: например, за счет разработки специализированного оборудования, сокращения времени вывода на экран, разреженности, оптимизации инфраструктуры и применения технологий обучения, таких как квантизация), но делать это без разбора будет тормозить возможности (в весенний период 2023 года им пришлось отказаться от проекта под кодовым названием «Arrakis», чтобы сделать ChatGPT более эффективным через разреженность, потому что проект показывал плохие результаты). Лучше потратить больше денег, чем потерять доверие клиентов — или еще хуже, инвесторов.
Таким образом, с этими двумя противоречивыми требованиями — возможностями и затратами — на вершине иерархии приоритетов OpenAI (чуть ниже всегда неопределенного AGI), мы можем сужать наши ожидания от GPT-5, даже если у нас нет официальной информации — мы знаем, что им важны оба фактора. Баланс отклоняется в сторону OpenAI, если мы добавим внешние обстоятельства, ограничивающие их возможности: нехватка GPU (не такая крайняя, как в середине 2023 года, но все еще существующая), нехватка данных в Интернете, нехватка дата-центров и отчаянный поиск новых алгоритмов.
Есть и последний фактор, который напрямую влияет на GPT-5 и подталкивает OpenAI к созданию наиболее способной модели, какую они могут позволить: их особое положение в индустрии.
OpenAI — это наиболее заметный стартап в области ИИ, передовой как в экономическом, так и в техническом плане, и мы затаиваем дыхание каждый раз, когда они что-то выпускают. Все взгляды направлены на них — конкуренты, пользователи, инвесторы, аналитики, журналисты, даже правительства — поэтому им нужно действовать крупно. GPT-5 должен оправдать ожидания и изменить парадигму. Несмотря на то, что Алтман сказал про итеративный развертывание и не шокирование мира, в каком-то смысле им действительно нужно потрясти мир. Даже если всего лишь чуть-чуть.
Вывод: несмотря на затраты и некоторые внешние ограничения — вычислительные мощности, данные, алгоритмы, выборы, социальные последствия — ограничивающие их возможности, ненасытная жажда увеличенных возможностей и необходимость немного поразить мир подтолкнут их к тому, чтобы идти так далеко, как только возможно. Давайте посмотрим, насколько далеко это может зайти.
Часть 3: Всё, что мы не знаем о GPT-5
GPT-5 и законы масштабирования
В 2020 году OpenAI разработал эмпирическую форму законов масштабирования, которая с тех пор определяет дорожную карту AI-компаний. Основная идея заключается в том, что для определения и даже предсказания производительности модели достаточно трех факторов: размера модели, количества токенов в обучении и вычислительных затрат на FLOPs (в 2022 году DeepMind уточнил законы и наше понимание того, как обучать вычислительно эффективные модели, что известно как «законы масштабирования Chinchilla», т.е. самые большие модели сильно недообучены; вам нужно масштабировать размер набора данных в той же пропорции, в которой вы масштабируете размер модели, чтобы максимально использовать доступные вычислительные ресурсы и достичь наиболее эффективного ИИ).
Новый набор законов масштабирования, о котором я упоминал выше, касается того, как модели могут масштабироваться теперь, когда компании могут балансировать вычислительную мощность между временем обучения и тестирования (впервые продемонстрировано для OpenAI o1). Это означает, что модели могут выделять больше вычислительных ресурсов в реальном времени, отвечая на ваши вопросы, и это может улучшить производительность без увеличения времени обучения. Я оставлю эту часть анализа за пределами статьи, потому что на данный момент это не исследованная территория — никто не знает, как это повлияет на производительность моделей.

Следующая суть стандартных законов масштабирования (как в оригинальной версии OpenAI, так и в пересмотренной версии DeepMind) предполагает, что с ростом вашего бюджета большая часть его должна быть выделена на масштабирование моделей (размер, данные, вычисления). (Даже если конкретные детали законов оспариваются, их существование, независимо от того, какими окажутся константы, в настоящее время не вызывает сомнений.)
Алтман заявил в 2023 году, что «мы находимся в конце эпохи гигантских моделей, и мы будем улучшать их другими способами». Один из многих способов, которыми этот подход повлиял на GPT-4 — и, безусловно, повлияет на GPT-5 — без отказа от масштабов состоял в том, чтобы сделать его Смешением Экспертов (MoE), а не крупной плотной моделью, как это было у GPT-3 и GPT-2.
MoE — это умная комбинация меньших специализированных моделей (экспертов), которые активируются в зависимости от природы входных данных (вы можете представить это как математика-эксперта для математических вопросов, креативного эксперта для написания художественной литературы и так далее) через механизм, который также является нейронной сетью, обучающейся распределять входные данные между экспертами. При фиксированном бюджете, архитектура MoE улучшает производительность и время вывода по сравнению с менее крупным плотным аналоги, потому что только небольшая часть специализированных параметров активна для любого заданного запроса.
Противоречат ли утверждения Алтмана о «конце эпохи гигантских моделей» или о переходе от плотных моделей к MoE законам масштабирования? Вовсе нет. Это, если угодно, более разумное применение уроков масштабирования с учетом других приемов, таких как оптимизация архитектуры (я ошибался, критикуя OpenAI за то, что они сделали GPT-4 MoE). Масштаб все еще остается ключевым в генеративном ИИ (особенно в языковых и мультимодальных моделях), просто потому, что это работает. Можно ли сделать так, чтобы это работало еще лучше, улучшая модели в других аспектах? Это отлично!
Единственный способ конкурировать на высшем уровне — это подходить к инновациям в области ИИ с целостным взглядом: нет смысла углубленно исследовать лучший алгоритм, если больше вычислений и данных могут помочь вам закрыть разрыв в производительности. Так же нет смысла тратить миллионы на H100, когда более простая архитектура или техника оптимизации могут сэкономить вам половину этих денег. Если сделать GPT-5 в 10 раз больше — это сработает, отлично. Если сделать его супер-MoE — это сработает, прекрасно.
Фридман спросил Алтмана, какие основные проблемы стоят перед созданием GPT-5 (вычислительные или технические/алгоритмические), и Алтман ответил: «Это всегда все эти вещи». Он добавил, что OpenAI делает действительно хорошо то, что «мы умножаем 200 средних по размеру элементов на один гигантский».
Искусственный интеллект всегда был областью компромиссов, но как только генеративный ИИ вышел на рынок и стал индустрией, приносящей прибыль, появился еще больше компромиссов. OpenAI балансирует с этим. В данный момент предпочтительная эвристика для поиска лучшего пути — следовать совету Ричарда Саттона из «Горького урока», который является неформальной формулировкой законов масштабирования. Вот как я бы резюмировал целостный подход OpenAI к решению этих компромиссов в одном предложении: сильно верьте в законы масштабирования, но не держите это мнение слишком строго в свете многообещающих исследований.
GPT-5 является продуктом этого целостного взгляда, поэтому он извлечет максимум из законов масштабирования — и всего остального, пока это приближает OpenAI к их целям. В каком направлении масштаб определяет GPT-5? Мой ответ прост: во всех направлениях. Увеличьте размер модели, увеличьте обучающий набор данных и увеличьте вычислительные ресурсы/FLOPs. Давайте сделаем некоторые грубые вычисления.
Размер модели
GPT-5 тоже будет моделью типа MoE (модели смешивания экспертов) (AI-компании в основном сейчас создают MoE по вполне понятным причинам; высокая производительность с эффективным выводом. Llama 3 — интересное исключение, вероятно, потому что она предназначена — особенно меньшие версии — для работы локально, чтобы пользователи с ограниченными ресурсами GPU могли запустить ее в своей ограниченной памяти). GPT-5 будет больше, чем GPT-4 (в общем количестве параметров, что означает, в случае если OpenAI не найдет лучшего архитектурного решения, чем MoE, что GPT-5 будет иметь либо больше экспертов, либо более крупные, чем GPT-4, в зависимости от того, что даёт лучший баланс между производительностью и эффективностью; есть и другие способы добавления параметров, но это кажется мне наиболее логичным).
Насколько большим будет GPT-5, неизвестно. Мы могли бы наивно экстраполировать тренд роста количества параметров: GPT, 2018 (117M), GPT-2, 2019 (1.5B), GPT-3, 2020 (175B), GPT-4, 2023 (1.8T, оценочно), но прыжки не соответствуют никакой четко определенной кривой (особенно потому, что GPT-4 — это модель MoE, поэтому это не полностью сопоставимое сравнение с другими). Еще одной причиной, почему эта наивная экстраполяция не срабатывает, является то, что разумный размер новой модели зависит от размера обучающего набора данных и количества GPU, на которых можно ее обучить (помните о внешних ограничениях, о которых я упоминал ранее; нехватка данных и оборудования).
Я нашел оценки размеров, опубликованные в других местах (например, 2–5T параметров), но считаю, что недостаточно информации для точного предсказания (все равно я подсчитал свою оценку, чтобы предоставить вам что-то интересное, даже если она в итоге окажется не очень точной).
Давайте посмотрим, почему делать обоснованные оценки размера сложнее, чем кажется. Например, вышеуказанное число 2–5T от Алана Томпсона основано на предположении, что OpenAI использует в два раза больше вычислительных ресурсов («10,000 → 25,000 NVIDIA A100 GPU с некоторыми H100») и вдвое больше времени обучения («~3 месяца → ~4–6 месяцев») для GPT-5 по сравнению с GPT-4.
GPT-5 уже обучался в ноябре, и последняя тренировка все еще шла месяц назад, поэтому удвоение времени обучения имеет смысл, но количество GPU указано неверно. К моменту, когда они начали обучение GPT-5, и несмотря на нехватку GPU H100, OpenAI имел доступ к большинству вычислительных ресурсов Microsoft Azure Cloud, т.е. «10k-40k H100». Таким образом, GPT-5 может быть больше 2–5T в три раза (я записал детали своих расчетов ниже).
Размер обучающего набора данных
Законы масштабирования Chinchilla показывают, что самые большие модели серьезно недообучены, так что нет смысла делать GPT-5 больше, чем GPT-4, без дополнительных данных для загрузки дополнительных параметров.
Даже если GPT-5 будет аналогичного размера (хотя я на это не ставлю, но это не нарушит законы масштабирования и может быть разумным в рамках нового алгоритмического подхода), законы Chinchilla предполагают, что больше данных также приведет к лучшей производительности (например, модель Llama 3 с 8B параметрами была обучена на 15T токенов, что является серьезным «переобучением», но при этом она все еще училась, когда они остановили обучение).
GPT-4 (1.8T параметров) оценивается как обученная на примерно 12–13 триллионах токенов. Если мы осторожно предположим, что GPT-5 того же размера, что и GPT-4, тогда OpenAI все равно может улучшить его, загрузив до 100 триллионов токенов — если они найдут способ собрать столь много! Если модель больше, тогда им понадобятся эти ценные токены.
Одним из вариантов для OpenAI было использовать Whisper для транскрибирования видео с YouTube (что они делали в нарушение TOS YouTube). Другим вариантом были синтетические данные, что уже является обычной практикой среди AI-компаний и станет нормой, когда «человеческие» данные интернета «закончатся». Я считаю, что OpenAI все еще выжимает последние остатки доступных данных и ищет новые способы обеспечить высокое качество синтетических данных.
(Возможно, они нашли интересный способ сделать последнее, чтобы улучшить производительность без увеличения числа токенов для предварительного обучения. Я исследовал эту часть в подразделе «логика» раздела «алгоритмические прорывы».)
Вычислительная мощность
Большее количество GPU позволяет создавать более крупные модели и больше эпох на одном и том же наборе данных, что в обоих случаях дает лучшую производительность (до некоторой точки, которую они еще не нашли). Чтобы сделать грубые выводы из всего этого поверхностного анализа, нам следует сосредоточиться на одном аспекте, который мы точно знаем изменился между периодом с августа 2022 года по март 2023 года (период обучения GPT-4) и сейчас: доступ OpenAI к тысячам H100 Azure и последующее увеличение доступных FLOPs для обучения следующих моделей.
Возможно, OpenAI также нашел способ дополнительно оптимизировать архитектуру MoE и вместить больше параметров при тех же затратах на обучение/вывод, возможно, они нашли способ создать синтетические данные, генерированные искусственным интеллектом, в токены высококачественно достойные GPT-5, но мы не можем быть уверены ни в том, ни в другом. Однако H100 Azure дает определенное преимущество, которое не следует игнорировать. Если есть AI-стартап, который выходит из нехватки GPU, это — OpenAI. Вычислительные мощности — это то, где затраты играют роль, но Microsoft, пока что, покрывает эту часть, поскольку GPT-5 дает отличные результаты (и пока не является AGI).
Моя оценка размера GPT-5
Предположим, что OpenAI использовал не 25k A100, как предлагает Томпсон, а 25k H100 для обучения GPT-5 (среднее значение «10k-40k H100», зарезервированных за OpenAI). Округляя цифры, H100 в 2-4 раза быстрее, чем A100 для обучения LLM (при аналогичных затратах). OpenAI мог бы обучить модель размером с GPT-4 за один месяц с таким количеством вычислительных ресурсов. Если GPT-5 понадобится им 4–6 месяцев, то оценка его размера составит 7–11T параметров (предполагая такую же архитектуру и данные для обучения). Это более чем в два раза превышает оценку Томпсона. Но имеет ли смысл делать его таким большим или лучше обучить меньшую модель на большем количестве FLOPs? Мы не знаем; возможно, OpenAI сделала еще один архитектурный или алгоритмический прорыв в этом году, чтобы повысить производительность без увеличения размера.
Теперь давайте проведем анализ, предполагая, что вывод является ограничивающим фактором (Алтман сказал в 2023 году, что OpenAI ограничено в вычислительных ресурсах как в обучении, так и в выводе, но он бы предпочел увеличить эффективность в последнем, что является признаком того, что затраты на вывод в конечном итоге превзойдут затраты на обучение). С 25k H100, OpenAI имеет для GPT-5 по сравнению с GPT-4 в два раза больше максимальных FLOPS, большие размеры пакетного вывода и возможность выполнять вывод в FP8 вместо FP16 (половинная точность). Это ведет к увеличению производительности в 2-8 раз при выводе. GPT-5 может быть размером до 10-15T параметров, что на порядок величины больше, чем у GPT-4 (если существующие конфигурации параллелизма, которые распределяют веса модели по GPU в момент вывода, не сломаются при таком размере, но я не знаю). OpenAI также может решить сделать его в 10 раз более эффективным, что синонимично снижению затрат (или некоторый взвешенный смешанный вариант из двух).
Еще одна возможность, которую я считаю заслуживающей внимания, поскольку OpenAI продолжает улучшать GPT-4, заключается в том, что часть вновь доступных вычислительных ресурсов будет перенаправлена на повышение эффективности/снижения затрат GPT-4 (или даже на полное освобождение от GPT-3.5; можно мечтать, не так ли?). Таким образом, OpenAI сможет получать доход от сомнительных пользователей, которые знают о существовании ChatGPT, но не готовы платить или не осознают, что разница между бесплатной версией 3.5 и платной версией 4 огромна. Я не буду комментировать стоимость услуги (не уверен, выйдет ли GPT-5 вообще на ChatGPT), потому что без точных характеристик невозможно сказать (размер/данные/вычисления — это неопределенность первого порядка, но цена — это неопределенность второго порядка).
Вывод: я оцениваю, что размер GPT-5 составит 7–11T параметров или 10–15T параметров, в зависимости от того, какую оценку я использую.
Часть 4: Алгоритмические прорывы в GPT-5
Это самая интересная часть (да, даже более интересная, чем предыдущая), и, согласно законам интересности, она также является самой спекулятивной. Экстраполировать законы масштабирования от GPT-4 к GPT-5 возможно, хоть и непросто. Попытка предсказать алгоритмические усовершенствования с учетом того, сколько неопределенности существует в данной области на данный момент, представляет собой гораздо большую задачу.
Лучшие эвристики заключаются в том, чтобы следить за людьми, связанными с OpenAI, обитать на альфа-ресурсах с высоким соотношением сигнал/шум и читать статьи, выходящие из ведущих лабораторий. Я делаю это лишь частично, так что прошу прощения за любые экстравагантные утверждения. Если вы дошли до этого момента, вы все равно слишком глубоко в моем бреде. Так что спасибо вам за это. Вот намек на то, чего мы можем ожидать (т.е. над чем работал OpenAI с момента выхода GPT-4):

Это, конечно, маркетинг Алтмана, но мы можем использовать это структурированное видение, чтобы извлечь ценные инсайты. Некоторые из этих возможностей больше ориентированы на поведенческую сторону (например, рассуждения, агенты), в то время как другие больше нацелены на потребителя (например, персонализация). Все они требуют алгоритмических прорывов. Вопрос в том, станет ли GPT-5 материализацией этого видения? Давайте разберем это и сделаем обоснованное предположение.
Мультимодальность
Несколько лет назад мультимодальность была мечтой. Сегодня это необходимость. Все ведущие компании в сфере ИИ (независимо от того, интересуют ли их AGI или нет) усердно работают над тем, чтобы дать своим моделям возможность захватывать и генерировать различные сенсорные модальности. Люди в мире ИИ склонны считать, что нет необходимости повторять все эволюционные черты, которые делают нас интеллектуальными, но мультимодальность мозга — это то, что они не могут исключить. Два примера этих усилий: GPT-4 может принимать текст и изображения, а затем генерировать текст, изображения и аудио. Gemini 1.5 может принимать текст, изображения, аудио и видео и генерировать текст и изображения.
Очевидный вопрос: куда движется мультимодальность? Какие дополнительные сенсорные навыки будут у GPT-5 (и у моделей ИИ следующего поколения в целом)? Наивно можно считать, что у людей пять чувств, и когда они будут интегрированы, на этом все. Но это не так, у людей на самом деле есть еще несколько чувств. Все ли они необходимы для того, чтобы ИИ был интеллектуальным? Следует ли нам реализовать те модальности, которые есть у животных, а у нас — нет? Это интересные вопросы, но мы говорим о GPT-5, поэтому я остановился на немедленных возможностях, о которых OpenAI давал нам намеки.
Voice Engine предполагает, что эмоциональный/человеческий синтетический аудиоконтент достаточно реализован. Он уже внедрен в ChatGPT, так что он будет и в GPT-5 (возможно, не с самого начала). Наиболее актуальной, но еще не решенной областью является генерация видео. OpenAI анонсировала Sora в феврале, но не выпустила его. The Information сообщила, что генеральный директор Google DeepMind, Демис Хассабис, сказал: «Возможно, Google будет сложно догнать OpenAI с Sora». Учитывая возможности Gemini 1.5, это не подтверждение ограничений Google в разработке ИИ, а признание того, насколько впечатляющим является достижение Sora. Включит ли OpenAI его в GPT-5? Они тестируют первые впечатления среди художников и TED; трудно предсказать, что произойдет, когда любой сможет создавать видео на любую тему.
The Verge сообщила, что Adobe Premiere Pro интегрирует инструменты ИИ для видео и, возможно, OpenAI Sora. Я предполагаю, что OpenAI сначала выпустит Sora как отдельную модель, но в конечном итоге объединит его с GPT-5. Это будет намеком на обещание «не шокировать мир», учитывая, насколько мы привыкли к текстовым моделям по сравнению с видео. Они будут постепенно предоставлять доступ к Sora, как это было с GPT-4 Vision, а затем дадут GPT-5 возможность генерировать (и понимать) видео.
Робототехника
Алтман не упоминает гуманоидные роботы или воплощение в своем слайде о «возможностях ИИ», но партнерство с Figure (и эффектная демонстрация, в которую вам не стоит верить, даже если она реальна) говорит о будущем OpenAI в этой области (заметьте, что мультимодальность касается не только глаз и ушей, но также и тактильных ощущений, проприоцепции и моторных систем, то есть ходьбы и ловкости. В определенном sentido, робототехника является общим фактором между мультимодальностью и агентами.
Одно из моих наиболее уверенных мнений, которое менее принято в кругах ИИ, заключается в том, что тело является необходимым условием для достижения уровня интеллекта человека, независимо от того, основано ли оно на кремнии или углероде. Мы склонны думать, что интеллект заключается в нашем мозге, но это интеллектуальная несправедливость по отношению к критической роли, которую наши тела (и тела других) играют в восприятии и познании. Мелани Митчелл написала обзор в журнале Science на тему общего интеллекта и высказалась о воплощении и социализации:
«Многие изучающие биологический интеллект также скептически относятся к тому, что так называемые «когнитивные» аспекты интеллекта можно отделить от его других мод и запечатлеть в лишенной тела машине. Психологи показали, что важные аспекты человеческого интеллекта основаны на воплощенных физических и эмоциональных опытах. Доказательства также показывают, что индивидуальный интеллект глубоко зависит от участия человека в социальных и культурных условиях. Способности понимать, координироваться с другими и учиться у людей, вероятно, гораздо важнее для успеха человека в достижении целей, чем «оптимизационная мощь» индивидуума.
Я предполагаю, что OpenAI возвращается к робототехнике (увидим, в какой степени GPT-5 сигнализирует об этом переходе). Они отказались от этого не из философских соображений (даже если некоторые члены компании все еще говорят такие вещи, как «генерация видео приведет к AGI, моделируя все», что предполагает, что тело не обязательно), а из прагматических соображений: недостаток доступных данных, недостаточная сложность симуляций для экстраполяции результатов в реальный мир, слишком дорогие и медленные эксперименты в реальном мире, парадокс Моравеца и т. д.
Возможно, они возвращаются к робототехнике, передавая работы партнерам, сосредоточенным исключительно на этом. Робот Figure 02 с GPT-5 внутри, способный к агентному поведению и рассуждениям — и при этом умеющий ходить — стал бы замечательным инженерным достижением и настоящим чудом.
Рассуждение
Это важный вопрос, который, возможно, появится в GPT-5 совершенно новым образом. Алтман сказал Фридману, что GPT-5 будет гораздо умнее предыдущих моделей, что является более коротким способом сказать, что он будет гораздо более способным к рассуждению. Если человеческий интеллект выделяется среди животного интеллекта чем-то одним, так это тем, что мы можем рассуждать о вещах. Рассуждение, чтобы дать вам определение, — это способность выводить знания из существующих знаний, комбинируя их с новой информацией согласно логическим правилам, таким как дедукция или индукция, чтобы приблизиться к истине. Это то, как мы строим мысленные модели мира (горячая тема в ИИ в настоящее время) и как мы разрабатываем планы для достижения целей. Короче говоря, это способ, которым мы создали чудеса вокруг нас, которые мы называем цивилизацией.
Сознательное рассуждение сложно. Точнее, оно кажется нам сложным. И это вполне оправдано, потому что это когнитивно тяжелее, чем большинство других вещей, которые мы делаем; умножение четырехзначных чисел в уме — это способность, зарезервированная для самых способных умов. Если это так сложно, как же наивные калькуляторы могут делать это мгновенно с большими числами? Это относится к парадоксу Моравеца (который я только что упомянул мимоходом). Ханс Моравец заметил, что ИИ может делать вещи, которые кажутся нам тяжелыми, такие как арифметические операции с большими числами, очень легко, но при этом сталкивается с трудностями при выполнении задач, которые кажутся наиболее обыденными, таких как ходьба по прямой.
Но если глупые устройства могут мгновенно выполнять арифметику на уровне бога, почему ИИ гораздо меньше, чем люди, справляется с рассуждением для решения новых задач или проблем? Почему способность ИИ обобщать так плоха? Почему он демонстрирует превосходный кристаллизованный интеллект, но ужасный текучий интеллект? Ведется постоянная дискуссия о том, могут ли современные передовые LLMы, такие как GPT-4 или Claude 3, вообще рассуждать. Я считаю, что интересный момент заключается в том, что они не могут рассуждать так, как мы, с такой же глубиной, надежностью, устойчивостью или обобщаемостью, а только «в крайне ограниченных рамках», по словам Алтмана. (Высокие оценки в таких «рассуждательных» бенчмарках, как MMLU или BIG-bench, не означают, что они способны на рассуждения, аналогичные человеческим; это может быть достигнуто с помощью запоминания и сопоставления шаблонов, не говоря уже о загрязнении данных.)
Мы могли бы утверждать, что это «проблема навыков» или что «выборка может доказать наличие знаний, но не их отсутствие», что обе являются справедливыми и обоснованными причинами, но не могут в полной мере объяснить абсолютный провал GPT-4, например, в испытании ARC, которое люди могут решить. Эволюция могла предоставить нам ненужные преграды для рассуждения, поскольку это неэффективный процесс оптимизации, но есть много эмпирических данных, которые показывают, что ИИ все еще отстает от нас в том, что Моравец не предсказывал.
Все это служит введением к тому, что я считаю глубокими техническими проблемами, лежащими в основе недостатков рассуждений ИИ. Главный фактор, который я вижу, заключается в том, что компании ИИ слишком сильно сосредоточились на обучении с подражанием, то есть на сборе огромных объемов данных, созданных человеком, в интернете и на их использовании для обучения огромных моделей, чтобы они могли учиться, пиша так, как пишем мы, и решая проблемы так, как мы решаем проблемы (это то, что делают чистые LLMы). Логика заключалась в том, что, обеспечив ИИ данными людей, созданными на протяжении веков, он научится рассуждать так, как это делаем мы, но это не сработало.
Существуют два важных ограничения подхода обучения с подражанием: Во-первых, знания в интернете в основном являются явными знаниями (know-what), но неявные знания (know-how) не могут быть точно переданы словами, поэтому мы даже не пытаемся — то, что вы находите онлайн, в основном является готовым продуктом сложного итеративного процесса (например, вы читаете мои статьи, но не осознаете, сколько черновиков мне пришлось пройти). (Я вернусь к различию между явными и неявными знаниями в разделе о агентах.)
Во-вторых, подражание — это лишь один из множества инструментов в арсенале обучения ребенка. Дети также экспериментируют, пробуют и ошибаются, и играют самостоятельно — мы наслаждаемся несколькими средствами обучения, помимо подражания, взаимодействуя с миром через обратные связи, которые обновляют знания, и механизмы интеграции, которые накладывают их на существующие знания. LLMы лишены этих критически важных инструментов рассуждения. Однако они не являются незнакомыми в ИИ: это то, что AlphaGo Zero от DeepMind сделала, чтобы уничтожить AlphaGo со счетом 100–0 — без каких-либо человеческих данных, просто играя игры против себя, используя комбинацию глубокого обучения с подкреплением (RL) и поиска.
Кроме этого мощного механизма циклов проб и ошибок, и AlphaGo, и AlphaGo Zero имеют дополнительную функцию, которой, еще раз, даже лучшие LLMы (GPT-4, Claude 3 и т.д.) сегодня не обладают: способность размышлять о том, что делать дальше (это обыденный способ сказать, что они используют алгоритм поиска, чтобы различать плохие, хорошие и лучшие варианты по сравнению с целью, контрастируя и интегрируя новую информацию с предыдущими знаниями). Возможность распределять вычислительную мощность в зависимости от сложности рассматриваемой задачи — это то, что люди делают постоянно (DeepMind уже тестировала этот подход с интересными результатами). Это то, что Даниэль Канеман назвал мышлением системы 2 в своей популярной книге «Thinking, Fast and Slow». Ёшуа Бенгио и Ян Леку все пытались дать ИИ способности «мышления системы 2».
Я считаю, что эти две особенности — самоподдержка/циклы/проб и ошибок и мышление системы 2 — являются многообещающими направлениями исследований для начала сокращения разрыва в рассуждениях между ИИ и людьми. Интересным является то, что сама по себе существование ИИ, обладающего этими способностями, таких как AlphaGo Zero от DeepMind — также AlphaZero и MuZero (которому даже не были даны правила игр) — контрастирует с тем фактом, что лучшие системы ИИ сегодня лишены их. Причина заключается в том, что реальный мир (даже просто лингвистический мир) гораздо сложнее «решить», чем шахматная доска: игра с несовершенной информацией, нечеткими правилами и наградами и несогласованным пространством действий с квази-бесконечными степенями свободы представляет собой практически невозможную задачу, которую вы найдете в науке.
Я полагаю, что преодоление этого разрыва между ИИ, играющими в игры с рассуждением, и ИИ, рассуждающими в реальном мире, является тем, на что направлены все текущие проекты по рассуждению. Данные приводят меня к мысли, что OpenAI уделяла особое внимание уходу от чистого обучения с подражанием, интегрируя мощь поиска и RL с LLMами. OpenAI o1 является примитивной попыткой этого, но недостаточной, чтобы заявить, что проблемы рассуждения ИИ были решены.
Возможно, ключевой фигурой в OpenAI, к которой стоит обратиться за подсказками по этому вопросу, является Ноам Браун, эксперт по рассуждениям ИИ, который присоединился к компании из Meta в июне 2023 года. В своем анонсирующем твите он сказал следующее:
«На протяжении многих лет я исследовал самоподдержку ИИ и рассуждение в играх, таких как покер и дипломатия. Теперь я буду исследовать, как сделать эти методы по-настоящему общими. Если нам повезет, однажды мы можем увидеть LLMы, которые будут в 1 000 раз лучше, чем GPT-4. В 2016 году AlphaGo победила Ли Седоля, что стало важным моментом для ИИ. Но ключевым моментом была способность ИИ «размышлять» около 1 минуты перед каждым ходом… если мы сможем обнаружить общую версию, выгода может быть огромной. Да, вывод может быть в 1 000 раз медленнее и дороже, но какую цену мы заплатим за новый препарат от рака? Или за доказательство гипотезы Римана?»
Полагаю, он всё четко изложил, как только вы получили контекст, который я представил выше. Более того, в недавнем твите, который с тех пор был удален, он сказал: «Вы не получите сверхчеловеческих показателей, улучшая обучение с подражанием на данных людей».
На недавней лекции в Sequoia Андрей Карпаты, который недавно покинул OpenAI, сказал нечто подобное:
«Я думаю, что люди все еще не видели, что возможно в этой области… Я считаю, что мы уже сделали первый шаг AlphaGo. Мы выполнили часть обучения с подражанием. Существует второй этап AlphaGo, который связан с RL, и люди еще не сделали этого… именно эта часть сделала AlphaGo успешным и сверхчеловеческим… Модель должна практиковаться самостоятельно… она должна понять, что работает для нее, а что нет» [он предполагает, что наши способы обучения не адаптированы к психологии ИИ].
Замечания Брауна и Карпаты о пределах обучения с подражанием перекликаются с тем, что сопредседатель DeepMind Шейн Легг сказал в подкасте Дваркеша Пателя, снова ссылаясь на AlphaGo:
«Чтобы получить настоящее творчество, вам нужно исследовать пространство возможностей и находить такие скрытые жемчужины [он говорит о знаменитом ходе 37 во втором матче AlphaGo против Ли Седоля]… Я думаю, что современные языковые модели… на самом деле не делают этого. Они действительно имитируют данные… человеческую изобретательность… которая приходит из Интернета».
Таким образом, чтобы выйти за пределы обучения с подражанием, необходимо интегрировать это с поиском, самонаблюдением, обучением с подкреплением и т. д. Существует несколько статей о том, как ввести способности поиска в LLMы или как обобщить самодейственность через игры и другие подсказки (например, Training Chain-of-Thought via Latent-Variable Inference, ReFT: Reasoning with Reinforced Fine-Tuning, ARES: Alternating RL and SFT for Enhanced Multi-Modal Chain-of-Thought Reasoning Through Diverse AI Feedback, Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters). Но нет окончательных доказательств того, что именно OpenAI использует для добавления навыков рассуждения в GPT-5, кроме o1, и мы не совсем знаем, как это работает (некоторые пытались обратным инженерным методом это выяснить с умеренным успехом).
Будут ли способности рассуждения GPT-5 + o1 столь же впечатляющими, как это предполагалось выше?
Ян Лекюн сказал, что мы должны «игнорировать делuge полный ерунды о Q* [Q* = o1]», утверждая, что все топовые лаборатории ИИ работают над аналогичными вещами (технология конвергирует на то, что возможно, поэтому это имеет смысл). Он обвинил Алтмана в том, что у него «долгая история самообмана», критикуя слова Алтмана предположительно о Q* за день до его увольнения в драме правления: «[в четвертый раз] я был в комнате, когда мы приоткрыли завесу невежества и продвинулись к границе открытия».
Но Лекюн также может пытаться защитить работу Meta или, возможно, он просто разочарован, что OpenAI получил Брауна, который создал Libratus (покер) и CICERO (дипломатия) в лаборатории Лекюна FAIR. (В пользу предупреждений Лекюна мы также должны отметить, что Карпаты говорит, что это еще не закончено, а Браун всего лишь намекал на свою будущую работу, а не на что-то, что уже существует.)
Вывод: Я предполагаю, что GPT-5 будет мультимодальным LLM с заметно улучшенными способностями рассуждения, заимствованными из o1. Кроме того, OpenAI продолжит исследовать, как объединить эти две линии исследований, полное объединение которых остается неуловимым.
Персонализация
Я постараюсь быть кратким. Персонализация заключается в том, чтобы предоставить пользователю более тесную связь с ИИ. Пользователи не могут сделать ChatGPT своим настраиваемым помощником в той степени, в которой им хотелось бы. Системные подсказки, тонкая настройка, RAG и другие техники позволяют пользователям направлять чат-бота к желаемому поведению, но этого недостаточно как с точки зрения знаний, которые ИИ имеет о пользователе, так и контроля, который пользователь имеет над ИИ (и данными, которые он отправляет в облако для получения ответа от серверов). Если вы хотите, чтобы ИИ узнал о вас больше, вам нужно предоставить больше данных, что, в свою очередь, снижает вашу конфиденциальность. Это ключевой компромисс.
Компании ИИ необходимо найти компромиссное решение, которое удовлетворит их и их клиентов, если они не хотят, чтобы клиенты приняли решение перейти на open-source, даже если это требует больше усилий (переход на Llama 3 делает этот шаг более привлекательным, чем когда-либо). Существует ли удовлетворительная среда между мощностью и конфиденциальностью? Я так не думаю; если вы хотите масштабироваться, вам нужно использовать облачные решения. OpenAI даже не пытается сделать персонализацию сильной стороной GPT-5. По одной причине: модель будет чрезвычайно большой и требовательной к вычислительным ресурсам, так что забудьте о локальной обработке и защите данных (большинство предприятий не будет комфортно отправлять свои данные OpenAI).
Существует еще что-то, помимо конфиденциальности и обработки на устройстве, что позволит открыть новый уровень персонализации (что уже достигли другие компании, в частности Google и Magic, хотя только Google уже выпустил модель с этой функцией): контекстные окна на несколько миллионов токенов.
Переход от задавания ChatGPT вопроса из двух предложений к заполнению окна подсказки 400-страничным PDF-файлом, который содержит десятилетнюю работу, значительно увеличивает применимость — так ChatGPT может помочь вам извлечь информацию, которая может быть скрыта в этом документе. Почему этого еще не было? Потому что выполнение вывода по такому количеству входных запросов было дорогостоящим, и с каждым добавленным словом это становилось квадратично более дорогим. Это известно как “квадратичное узкое место внимания”. Однако, похоже, код был сломан; новые исследования от Google и Meta предполагают, что квадратичное “узкое место” больше не существует.
Приложение Ask Your PDF является отличным, когда PDF-файлы могут быть бесконечными по длине, но теперь стало возможно нечто новое с окнами на миллион токенов, что было невозможно с окнами на сто тысяч токенов: категория приложений “Ask My Life”. Я не уверен, каков будет размер контекстного окна у GPT-5, но учитывая, что молодая стартап-компания Magic, похоже, достигла отличных результатов с окнами на несколько миллионов токенов — и учитывая, что Алтман явно указал на персонализацию как на необходимую возможность ИИ — OpenAI, по крайней мере, должна будет сопоставить это ожидание.
Надежность
Надежность — любимая тема скептиков. Я думаю, что ненадежность языковых моделей, например, их галлюцинации, — одна из основных причин, по которым люди не видят достаточно ясной ценностной схемы генеративного ИИ для того, чтобы начать платить за него, почему рост остановился и использование выровнялось, а также почему некоторые эксперты считают их «развлечением», но не инструментом, повышающим продуктивность (и даже когда это так, не всегда все проходит гладко). Это не опыт всех пользователей языковых моделей, но он достаточно заметен, чтобы компании не отрицали, что надежность — это проблема, которую им нужно решить (особенно если они ожидают, что человечество будет использовать эту технологию для помощи в случаях с высоким риском).
Надежность является ключевым фактором для любого технологического продукта. Так почему же так трудно добиться этого для крупных моделей ИИ? Я нашел полезной следующую концептуализацию: вещи вроде GPT-5 не являются ни изобретениями, ни открытиями. Их лучше описывать как открытые изобретения. Даже люди, которые занимаются разработкой современного ИИ (не говоря уже о пользователях или инвесторах), не знают, как интерпретировать то, что происходит внутри моделей, когда вы вводите запрос и получаете ответ. (Механистическая интерпретация — это горячая область исследований, направленная на решение этой проблемы, но она еще на ранних стадиях. Если вам это интересно, ознакомьтесь с работой Anthropic.)
Кажется, что GPT-5 и подобные ему устройства — это древние артефакты, оставленные передовой цивилизацией, и мы случайно нашли их в процессе археологических раскопок, связанных с кремнием. Это изобретения, которые мы обнаружили, и теперь пытаемся выяснить, что они себе представляют, как работают и как сделать их поведение понятным и предсказуемым. Ненадежность, которую мы воспринимаем, является лишь следствием недостаточного понимания этих артефактов. Вот почему этот недостаток остается нерешенным, хотя он обходится компаниям в миллионы из-за оттока клиентов и неуверенности со стороны предприятий.
OpenAI пытается сделать GPT-5 более надежным и безопасным с помощью жесткой настройки (RLHF), тестирования и конкурентного анализа. У такого подхода есть недостатки. Если принять, как я объяснил выше, что неспособность ИИ к рассуждению заключается в том, что «выборка может подтвердить наличие знания, но не его отсутствие», мы можем применить ту же идею к тестированию безопасности: выборка может подтвердить наличие трещин в безопасности, но не их отсутствие. Это означает, что сколько бы тестирования ни провела OpenAI, они никогда не могут быть уверены, что их модель совершенно надежна или совершенно безопасна от обхода, атак со стороны злоумышленников или внедрения искажений.
Улучшит ли OpenAI надежность, галлюцинации и внешние векторы атаки для GPT-5? Тенденция от GPT-3 к GPT-4 предполагает, что они это сделают. Смогут ли они решить эти проблемы? Не стоит на это рассчитывать.
Агенты
Эта секция, на мой взгляд, самая интересная во всей статье. Всё, что я написал до этого момента, имеет значение, в той или иной степени, для AI-агентов (с особым акцентом на рассуждения). Главный вопрос заключается в следующем: Будет ли у GPT-5 агентные способности или он останется, как и предыдущие версии GPT, стандартной языковой моделью, способной делать много вещей, но не способной планировать и действовать для достижения целей? Этот вопрос актуален по трем причинам, которые я изложу ниже: Во-первых, важность агентности для интеллекта трудно переоценить. Во-вторых, мы знаем, что примитивная версия этого возможна. В-третьих, OpenAI работает над AI-агентами.
Многие люди считают, что агентность — это умение рассуждать, планировать и действовать автономно с течением времени для достижения какой-то цели, используя доступные ресурсы — это недостающая связь между LLM и человеческим уровнем ИИ. Агентность, даже больше чем чистое рассуждение, является знаковым признаком интеллекта. Как мы видели выше, рассуждение — это первый шаг на пути туда — ключевая способность для любого разумного агента — но этого недостаточно. Планирование и действия в реальном мире (для ИИ хорошо подойдёт смоделированная среда как первая приближенность) — это навыки, которыми обладают все люди. С раннего возраста мы начинаем взаимодействовать с миром так, что это раскрывает нашу способность последовательного рассуждения, нацеленного на заранее определенные цели. Сначала это происходит бессознательно, без вовлечения рассуждений (например, плачущий малыш), но по мере взросления это становится сложным, сознательным процессом.
Один из способов объяснить, почему агентность необходима для интеллекта и почему рассуждения в вакууме не очень полезны, заключается в различии между явными и неявными (по умолчанию) знаниями. Давайте представим мощный ИИ, способный к рассуждениям, который воспринимает мир пассивно (например, ИИ-эксперт по физике). Чтение всех книг в интернете позволило бы ИИ поглотить и создать невообразимое количество явных знаний (know-what), которые можно формализовать, передать и записать на бумаге и в книгах. Однако, каким бы умным ни был ИИ в области физики, он всё равно будет лишён способности взять все эти формулы и уравнения и применить их, скажем, для получения финансирования на дорогостоящий эксперимент по обнаружению гравитационных волн.
Почему? Потому что это требует понимания социоэкономических структур мира и применения этого знания в неопределенных новаторских ситуациях с множеством движущихся частей. Эта способность обобщать выходит за пределы того, что может охватить любая книга. Это неявное знание (know-how); тот вид знания, который вы получаете, только действуя и учась у тех, кто уже знает, как это делать. Основная суть в том, что никакой ИИ не может быть полезно агентным и достигать целей в мире без способности сначала приобрести умения и неявное знание, каким бы великим он ни был в чистом рассуждении.
Чтобы приобрести умения, люди делают вещи. Но “действие” в полезном для обучения и понимания ключе требует следования планам действий к целям с опосредованными обратными связями, экспериментированием, использованием инструментов и возможностью интегрировать все это с уже существующим пулом знаний (что и предполагает целенаправленное рассуждение за пределами имитационного обучения, как в случае с AlphaZero). Таким образом, рассуждение для агента — это средство для достижения цели, а не цель сама по себе (вот почему оно бесполезно в вакууме). Рассуждение предоставляет новое явное знание, которое AI-агенты затем используют для планирования и действий, чтобы приобрести неявное знание, необходимое для достижения сложных целей. Это суть интеллекта; это окончательная форма ИИ.
Этот вид агентного интеллекта резко контрастирует с LLM, такими как GPT-4, Claude 3, Gemini 1.5 или Llama 3, которые плохо справляются с удовлетворительным проведением планов (ранние попытки агентности на основе LLM, такие как BabyAGI и AutoGPT, или неудачные эксперименты с автономией — это доказательства этого). На сегодняшний день лучшие ИИ являются субагентными или, употребляя более или менее официальную номенклатуру, это инструменты ИИ (Gwern имеет хороший ресурс на тему различия между инструментом ИИ и AI-агентом).
Итак, как нам перейти от инструментов ИИ к AI-агентам, которые могут рассуждать, планировать и действовать? Может ли OpenAI сократить разрыв между GPT-4, инструментом ИИ, и GPT-5, потенциально AI-агентом? Для ответа на этот вопрос нам нужно отойти назад от текущего фокуса и убеждений OpenAI относительно агентности и рассмотреть, существует ли путь оттуда. В частности, OpenAI, похоже, убеждена, что LLM — или более обобщённо алгоритмы предсказания токенов (TPA), что является обширным термином, включая модели для других модальностей, например, DALL-E, Sora или Voice Engine — достаточно для достижения AI-агентов.
Если верить позиции OpenAI, нам сначала нужно ответить на этот другой вопрос: Могут ли AI-агенты возникнуть из TPA, обходим необходимость в неявном знании или даже ручных механизмах рассуждения?
Логика за этими вопросами заключается в том, что великий предсказатель/симулятор ИИ — который теоретически возможен — должен был каким-то образом развить внутреннюю модель мира для точных предсказаний. Такой предсказатель мог бы обойти необходимость в приобретении неявного знания, обладая глубоким пониманием того, как работает мир. Например, вы не учитесь кататься на велосипеде по книгам, вам нужно на нем кататься, но если бы вы могли каким-то образом предсказать, что произойдет следующим, с произвольно высокой степенью детализации, этого могло бы быть достаточно, чтобы хорошо вкатиться с первого раза и на всех последующих поездках. Люди не могут этого сделать, поэтому нам нужна практика, но может ли ИИ? Давайте проясним это, прежде чем перейдем к реальным примерам AI-агентов, включая то, над чем работает OpenAI.
Алгоритмы предсказания токенов (TPA) невероятно мощные. Так мощные, что вся современная генеративная ИИ построена на предположении, что достаточно способный TPA может развить интеллект. GPT-4, Claude 3, Gemini 1.5 и Llama 3 являются TPA. Sora — это TPA (создатели которой утверждают, что “приведет к AGI, моделируя все”). Voice Engine и Suno — это TPA. Даже маловероятные примеры, такие как Figure 01 (“видео вход, траектории выход”) и Voyager (ИИ-игрок в Minecraft, использующий GPT-4), в основном также являются TPA. Но чистый TPA, возможно, не является лучшим решением для всего. Например, AlphaGo и AlphaZero от DeepMind не являются TPA, но, как я отметил в разделе “рассуждений”, это умное сочетание обучения с подкреплением, поиска и глубокого обучения.
Может ли интеллектуальный AI-агент появиться из GPT-5, обученного как GPT-4, в качестве TPA, или для того, чтобы сделать GPT-5 агентом, OpenAI нужно найти совершенно другую функцию для оптимизации или даже новую архитектуру? Может ли (гораздо) лучший GPT-4 в конечном итоге развить агентные способности или нужен ли AI-агент быть чем-то совершенно иным? Илья Сутскевер, научный руководитель ранних успехов OpenAI, не сомневается в мощи TPA:
… Когда мы обучаем большую нейронную сеть точно предсказывать следующее слово в различных текстах из интернета … мы учим модель мира … может показаться, что мы просто изучаем статистические корреляции в тексте, но на самом деле, чтобы “просто изучить” статистические корреляции в тексте, чтобы действительно хорошо их сжать, нейронная сеть изучает некоторое представление процесса, который производит текст. Этот текст на самом деле является проекцией мира… именно это и изучается, точно предсказывая следующее слово.
Билл Пиблс, один из создателей Sora, пошел еще дальше в недавней беседе:
По мере того как мы продолжаем масштабировать эту парадигму [TPA], мы считаем, что в конечном итоге она должна моделировать, как думают люди. Единственный способ создать поистине реалистичное видео с поистине реалистическими последовательностями действий — это иметь внутреннюю модель того, как работают все объекты, люди и т.д., окружающая среда.
Вы можете не разделять эту точку зрения, но мы можем спокойно экстраполировать аргументы Сутскевера и Пиблса, чтобы понять, что OpenAI, невзирая на внутренние дебаты, согласны. Если это сработает, этот подход опровергнет идею о том, что ИИ нужно захватывать неявное знание или конкретные механизмы рассуждения для планирования и действий, чтобы достигать целей и быть интеллектуальным. Возможно, всё дело только в токенах.
Я не разделяю позицию OpenAI по одной причине: они не обошли проблему неявного знания. Они просто переместили её в другое место. Теперь проблема заключается не в том, чтобы научиться рассуждать, планировать и действовать, а в том, чтобы моделировать миры. Они хотят решить, буквально, проблему предсказания. Пиблс упоминает об этом так спокойно, что это кажется неважным. Но разве не труднее создать идеального предсказателя/симулятора, чем создать сущность, которая может планировать и действовать в мире? Возможно ли даже создать ИИ, который мог бы моделировать “поистине реалистические последовательности действий”, как утверждал Пиблс на своей беседе? Я не думаю так — я не думаю, что мы можем это построить, и не думаю, что мы смогли бы оценить такую способность каким-либо образом. Возможно, доверие OpenAI к Грустному Уроку зашло слишком далеко (или, возможно, я ошибаюсь, мы увидим).
В любом случае, сегодня у ИИ-компаний мало возможностей — никто не знает, как построить системы планирования/действия, хотя Янн ЛеКун продолжает пытаться — поэтому они подходят к проблеме агентности с помощью трансформаторных TPA в форме LLM (включая OpenAI), нравится им это или нет, потому что это лучшая доступная технология. Давайте начнем с существующих прототипов, а затем перейдем к тому, что мы знаем о усилиях OpenAI.
Помимо примеров, которые я уже упомянул (например, BabyAGI, AutoGPT, Voyager и т.д.), есть и другие попытки создать агентов на основе LLM. Первая из них, которая привлекла моё внимание, появилась до ChatGPT. В сентябре 2022 года Adept AI анонсировала первую версию того, что они назвали Action Transformer, “крупномасштабным трансформером, обученным использовать цифровые инструменты” на основе видеозаписей людей. Они выпустили несколько демонстраций, но мало что было сделано далее. Год назад два сооснователя покинули компанию, что совершенно не является хорошим признаком (The Information сообщила, что Adept готовит запуск ИИ-агента этим летом. Посмотрим, как это пройдет). Ещё одна молодая стартап-компания, которая недавно присоединилась к “золотой лихорадке” AI-агентов, это Cognition AI, наиболее известная как создатель Devin, “первого ИИ-программиста” (у которого теперь есть открытая версия, OpenDevin). Всё шло хорошо сначала, но затем вышел обзорный видеоролик под названием “Разоблачение Devin”, который стал вирусным и показал, что Cognition переоценивала способности Devin. Результат? Cognition вынуждена была публично признать, что Devin недостаточно хорош, чтобы “зарабатывать деньги, выполняя запутанные задачи на Upwork”.
Это чисто программные агенты. Существует ещё одна ветвь, хотя она, безусловно, даже сложнее: устройства-агенты ИИ. Самыми известными примерами являются Rabbit R1 и Humane AI Pin. Обзоры на R1 выходят, так что мы подождем их (примерно в те же сроки, когда этот пост запланирован для публикации). Обзоры на Humane AI Pin вышли на прошлой неделе, и они абсолютно разрушительные. Если вы не читали мой “Weekly Top Picks #71”, вы можете почитать обзор от The Verge здесь или посмотреть видео от Marques Brownlee здесь.
Просто знайте, что вывод, принимая во внимание все вышеизложенные доказательства, заключается в том, что AI-агенты на основе LLM пока не существуют. Может ли OpenAI добиться большего?
Мы знаем очень мало о попытках OpenAI в области агентов. Мы знаем, что Андрей Карпаты “строил своего рода JARVIS”, прежде чем покинуть OpenAI (почему он бы уехал, если бы работал в лучшей AI-компании с самой многообещающей будущей перспективой для ИИ?) Business Insider сообщила, что GPT-5 будет иметь “способность вызывать ИИ-агентов, разрабатываемых OpenAI для выполнения задач автономно”, что крайне неопределенно. The Information сообщала о новой информации ранее на этой неделе:
OpenAI тихо проектирует компьютерные агенты, которые могли бы управлять компьютером человека и одновременно работать с различными приложениями, такими как передача данных из документа в электронную таблицу. В отдельности OpenAI и Meta работают над вторым классом агентов, которые могут справляться со сложными веб-задачами, такими как создание маршрута и бронирование путешествий на его основе.
Но даже если эти проекты увенчаются успехом, это не совсем то, что я описал выше как AI-агентов с автономными возможностями, схожими с человеческими, которые могут планировать и действовать для достижения целей. Как отмечает The Information, компании используют свои маркетинговые возможности, чтобы нивелировать концепцию, превращая “AI-агентов” в “широкий термин”, вместо того чтобы отступать от своих амбиций или подниматься до технической сложности. Бен Ньюхаус из OpenAI говорит, что они создают то, что “могло бы стать продуктом с нуля, определяющим промышленность, который опирается на последние и лучшие из наших предстоящих моделей”. Посмотрим на это.
В заключение этой подсекции об агентах, я верю, что OpenAI ещё не готова совершить финальный шаг к AI-агентам с самым большим релизом. Ещё много работы предстоит сделать. TPA, несмотря на то, что это единственное потенциальное решение на данный момент (пока не будут решены проблемы рассуждений, о которых я говорил выше), не будут достаточны для достижения нужных агентных способностей таким образом, чтобы люди стали рассматривать их для серьезных проектов.
Ставлю на то, что GPT-5 будет мультимодальной LLM, как те, что мы видели ранее — улучшенная версия GPT-4, если хотите. Вероятно, его окружат системы, которых ещё нет в GPT-4, включая способность подключаться к модели AI-агента для выполнения автономных действий в интернете и на вашем устройстве (но это будет далеко от настоящей мечты о человеческом AI-агенте). В то время как мультимодальность, рассуждения, персонализация и надежность — это характеристики системы (все они будут улучшены в GPT-5), агент — это совершенно отдельная сущность. GPT-5 не нужно быть агентом, чтобы наслаждаться силой агентности. Вероятно, это будет своего рода примитивный “менеджер AI-агентов”, возможно, первый, который мы согласны признавать как таковой.
Вывод: OpenAI интегрирует GPT-5 и AI-агентов на уровне продуктов, чтобы проверить ситуацию. Они также не выпустят GPT-5 и флот AI-агентов одновременно. Я предполагаю, что OpenAI считает способности агентности более сложными для контроля, чем “просто” лучшая мультимодальная LLM, поэтому они будут запускать AI-агентов гораздо более медленно. Повторюсь, с акцентом, на ранее упомянутую цитату Ньюхауса, чтобы прояснить, почему я так считаю: “Мы строим то, что… может стать продуктом, определяющим отрасль, который использует лучшие и последние из наших предстоящих моделей [подчеркнуто мной].” Продукт (AI-агент), который использует лучшее из предстоящих моделей (GPT-5).
В заключение
Вот и всё.
Поздравляю, вы только что прочитали 14,000 слов о GPT-5 и его окрестностях!
Надеюсь, это помогло вам лучше понять не только сам GPT-5 (полную картину мы увидим, когда он выйдет), но и то, как думать об этих вещах, о многих частях, которые должны двигаться в гармонии, чтобы сделать это возможным, и о множестве соображений, необходимых для более полного понимания будущего.
Это был увлекательный эксперимент — углубиться в такую тему (если вам нравятся сверхдлинные статьи подобного рода, я постараюсь сделать больше, когда найдется время). Надеюсь, это было интересно и полезно и для вас.
Источник статьи: albertoromgar.medium.com





Обсуждение закрыто.